
Leiden University Centre for Digital Humanities
Small Grants Past Research Projects
The LUCDH foster the development of new digital research by awarding a number of Small Grants each year. These are our past awardees.
Small Grants 2025 Research Projects
Automatic Recognition of Still Images of Signs in Print Dictionaries of Sign Languages
Nargess Asghari
Despite advances in language technology for spoken languages, sign languages are still left behind. The limited available sign language technology primarily relies on video datasets of (Western) sign languages. The present project explores the possibilities for automatic recognition of signs in print sign language dictionaries.
Even though the number of video-based dictionaries is growing, most sign language dictionaries, including historical ones, are in print format. Since sign languages are visual-spatial languages produced dynamically in the 3-dimensional space, their rendition on paper means going from 4D (space and time) to 2D (flat paper). There is no standardised way to represent a sign on paper (eg, the selected ‘state’ of the sign or the camera angle or viewpoint); arrows and other symbols are commonly used to indicate dynamic properties of signs (see examples below).
In this project, we focus on the classification of static images of signs. We will create a labelled dataset of sign images from a representative set of sign language dictionaries. The created dataset will be the first of its kind with still images of lexical signs. We will use out-of-the-box pose estimation models to identify pose keypoints (landmarks) in images. Next, we will train different machine learning models and evaluate their applicability for the intended classification task.
The outcomes of this exploratory project will inform the future development of computational tools for analysing sign language data in various formats. Such tools will facilitate quantitative measurement of lexical variation within and across languages and over time.

a) Photograph of a Guinea-Bissau SL signer signing câmara de filmar (‘film camera’); two hands depict the way a camera is held in front of the face. Coloured circles indicate the body joint locations automatically estimated by the MediaPipe pose estimation model. (b) Drawing of two hands for the sign table (‘table’) in French SL; arrows indicate the movement path of the two extended index fingers that are outlining a rectangle. (c) Drawing of a French SL signer in 19th-century attire signing chameau (‘camel’). A slightly curved B-hand (palm down) is held next to the waist; a wavy line indicates the movement path outlining camel humps.
Image credits:
(a) Martini, M., & Morgado, M. (2008). Dicionário escolar de Língua Gestual Guineense. Surd'Universo.
(b) & (c) Pélissier, P. (1856). Iconographie des signes: faisant partie de l'enseignement primaire des sourds-muets. Paris: Imprimerie et libraire de Paul Dupont
Determiners Lost & Found
Sjef Barbiers, Irina Morozova & Stephan Raaijmakers
There are languages with and without determiners, i.e. function words such as a and the in English. Native speakers of determiner languages like Dutch and English know intuitively when a syntactic/semantic/pragmatic context requires a determiner to be present or absent, and whether it should be definite or indefinite. On the other hand, it is very hard for L1 speakers of a determinerless language such as Russian to learn the correct use of determiners even if they are highly proficient L2 speakers of the determiner language. The linguistic conditions for the correct use of determiners are very complex and have not been described and understood in full. This pilot project concentrates on two descriptive questions (1,2), and two methodological questions involving computational tools (3,4):
- What kind of determiner use patterns does an L2 speaker of English and Dutch with Russian as an L1 show?
- What is the role of L1 transfer in these patterns?
- What traditional NLP-methods (tagging, parsing) are most suitable for automatic extraction of determiner errors?
- How can we use recent Large Language Models (LLMs) as tools for the detection and repair of determiner errors in both languages?

Transcribe the Archive
Carmen van den Bergh
Among the many texts housed in a literary repository, such as archives and special collections, it is the genre of the letter that offers us a candid glimpse into the inner workings of the creative mind of the sender. The genre remains, until today, largely understudied in the literary field and there are many reasons for this negligence, from a low editorial prestige to accessibility. (Douglas 2013)
A number of factors that complicated research of archival letters until recently, have been made less decisive with the entrance of modern technologies and the still evolving field of DH. Letters are now easier to access and to preserve. Deciphering difficult-to-read writings is made faster by increasingly sophisticated OCR software and more archives are willing to participate in digitization projects. Unfortunately, many literature scholars are still deterred from using DH in their research, often due to high costs of tools, out of fear of not being able to do it, or lack of time to delve into the matter. (Willaert, Speelman, Truyen 2018). Also, researchers are often asked to be multilingual. And this specialist knowledge of languages is becoming less evident, in a period of budget cuts.
We don’t have to look far in foreign archives to find real gems. Our own Special Collections at Leiden University Library have a treasure trove of letters from prominent people (writers, philosophers, intellectuals, botanists, kings and popes) who sought contact with Dutch professors. The letters are written in Latin, in German, in French, in Italian. The use of AI tools such as Transkribus and Omeka is not intended to undermine or replace the work of the researcher, but can help the researcher to accelerate and automate certain processes (such as handwriting recognition, extrapolation of metadata and transcribing the letters in multiple languages), thus leaving more time for content analysis, giving modern-day scholars the chance to recreate and study the networks of epistolary exchanges between European and Dutch courts, notables and contacts throughout time.
The Role of ChatGPT as a Translator in Intercultural and Interlingual Health Communication between Migrant Patients and General Practitioners in the Netherlands
Tian Yang & Susana Valdez
As global migration increases, healthcare systems face increasing challenges in overcoming language barriers between providers and migrant patients with limited proficiency. These barriers significantly hinder access to healthcare services, often leading to health inequality. Recent technological advancements have introduced machine translation (MT) tools like Google Translate (GT) as cost-effective, accessible alternatives to traditional solutions such as professional and ad-hoc interpreters. MT tools are increasingly used to access medical information, translate documents, schedule appointments, and facilitate communication during consultations. Despite their potential, concerns persist regarding accuracy, cultural nuance, data privacy, and trust in MT tools within healthcare. Research is needed to explore users' perceptions in MT to assess its effectiveness and limitations in bridging language gaps in healthcare. These insights will help refine MT tools to address the complexities of medical communication, ultimately improving healthcare outcomes and promoting equitable healthcare.
This study will recruit 12 Chinese migrant patients with limited English proficiency, along with their general practitioners (GPs), who will provide consent to participate. All patients will use Google Translate as needed during their diagnostic process.
- Observations will be conducted during consultations, focusing on communication effectiveness, challenges encountered, and how GT is integrated into the consultation.
- Semi-structured interviews with patients and GPs will explore their perceptions of GT, including comprehension, usability, challenges, concerns, and trust.
- Questionnaires will assess user satisfaction, comfort, and the perceived effectiveness of GT in medical consultations.
PROJECT UPDATE
19 January 2026
Drawing on in-depth interviews with 20 Chinese migrants residing in the Netherlands, participants were invited to use ChatGPT to support communication with general practitioners (GPs) and to subsequently reflect on their experiences. A thematic analysis of the interview data reveals five key findings.
First, participants perceived ChatGPT as a valuable communicative aid. It was praised for its perceived consistency and relatively high accuracy, as well as for its dual role as both a translation tool and an informational consultant. Second, the use of ChatGPT significantly alleviated anxiety and communicative stress associated with language barriers, thus enhancing their sense of autonomy and engagement in interactions with GPs. Third, concerns regarding data privacy were relatively limited. Most participants reported adopting a strategic approach to risk management. Fourth, the study identified several challenges in using ChatGPT during clinical encounters, including inaccurate speech recognition, delayed response times, feelings of awkwardness during face-to-face consultations, and a perceived lack of cultural sensitivity when interpreting communicative nuances specific to medical contexts. Finally, participants proposed several improvements to better support clinical communication, such as enhanced speech recognition accuracy, faster processing speed, and the introduction of a dedicated medical mode tailored to healthcare interactions.
This study also has several implications for future research. First, for many participants, this was their first experience using ChatGPT to navigate language barriers in healthcare settings. The majority expressed satisfaction with the tool and indicated a willingness to recommend it to others. These findings provide valuable user-centred insights that can inform the further development of translation functions in language AI tools to better support medical communication. Second, as users increasingly adapt to the translation and information-seeking capabilities of large language models (LLMs), there is growing potential to integrate translation, health information access, and healthcare navigation into a single, unified system. This study contributes empirical evidence to ongoing discussions about the role of LLMs as “one-stop” communicative infrastructures in healthcare contexts. Third, future studies could build on this work by systematically comparing the translation and communicative performance of different LLMs in healthcare settings. Such comparative research would offer important insights into the strengths and limitations of various AI tools and support evidence-based implementation in clinical practice.

Small Grants 2024 Research Projects
Dear Digital Diary: An Exploration of the Huydecoper Diaries (1648-1704) through Handwritten Text Recognition
Tessa de Boer & Ramona Negrón & Jessica den Oudsten
This project focuses on Joan Huydecoper van Maarsseveen (1625-1704). Huydecoper was a prominent individual who served as Burgomaster, Director of the Dutch East India Company, and Council in the Admiralty in Amsterdam. His diaries, including copies of his letters and lists of expenses, written between 1648 and 1704, have survived (Utrechts Archief). They provide a wealth of information about a variety of themes. For one, they provide a unique insight into Huydecoper's interactions with the Amsterdam elite. But the information in his diaries extends far beyond. Huydecoper corresponded, for example, with his servants and schoolmasters, as well as with scholars, diplomats, and merchants worldwide, in Dutch, French, Italian, and Latin.
Yet, despite the potential of his diaries as a source, they remain understudied. The primary obstacles for historians are the extensive volume of the diaries and Huydecoper's challenging handwriting. Our aim is, therefore, to make his diaries searchable by utilizing the latest digital methods.
The project has four principal goals:
- Develop a high-quality HTR model to generate instant transcriptions for a historically relevant collection of primary sources. This will transform the currently inaccessible collection into a searchable full-text database, saving time and increasing research efficiency.
- Develop a research agenda based on the primary source, utilizing collective expertise to identify priorities across historical subfields. This involves raising awareness of the source and the developed search tool.
- Train a promising student in paleography and cutting-edge digital tools, bridging the gap between traditional and digital methodologies in source work.
- Promote collaboration between academic and industrial expertise by working with archives.
The successful implementation of the HTR model will drastically enhance accessibility to the Huydecoper Diaries, offering new perspectives on various historiographical debates.

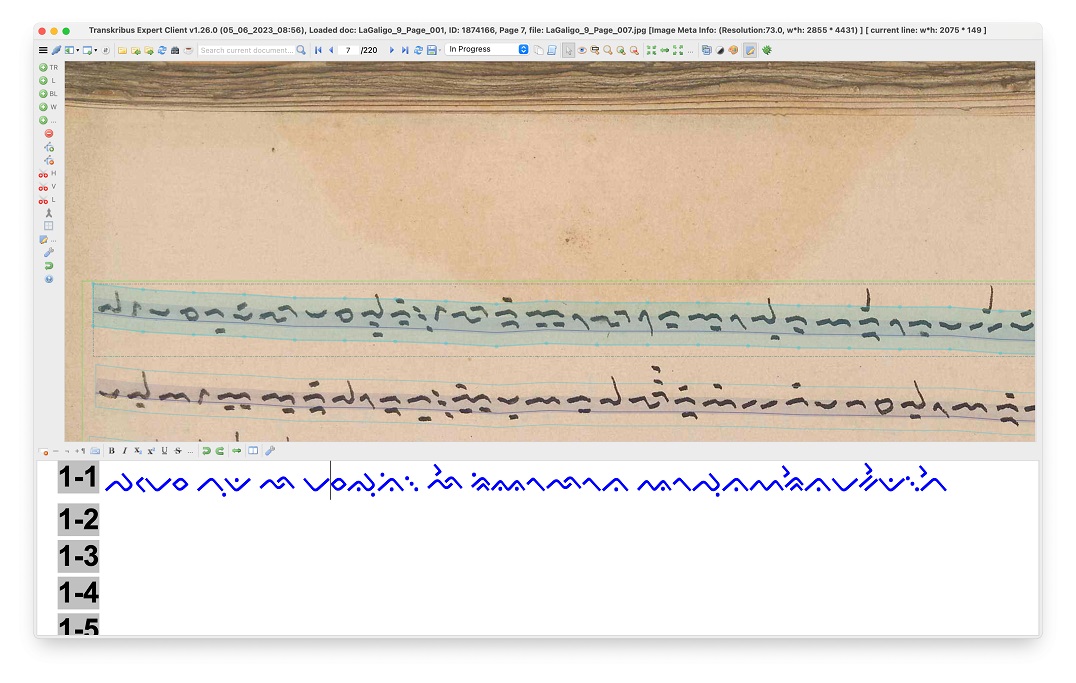
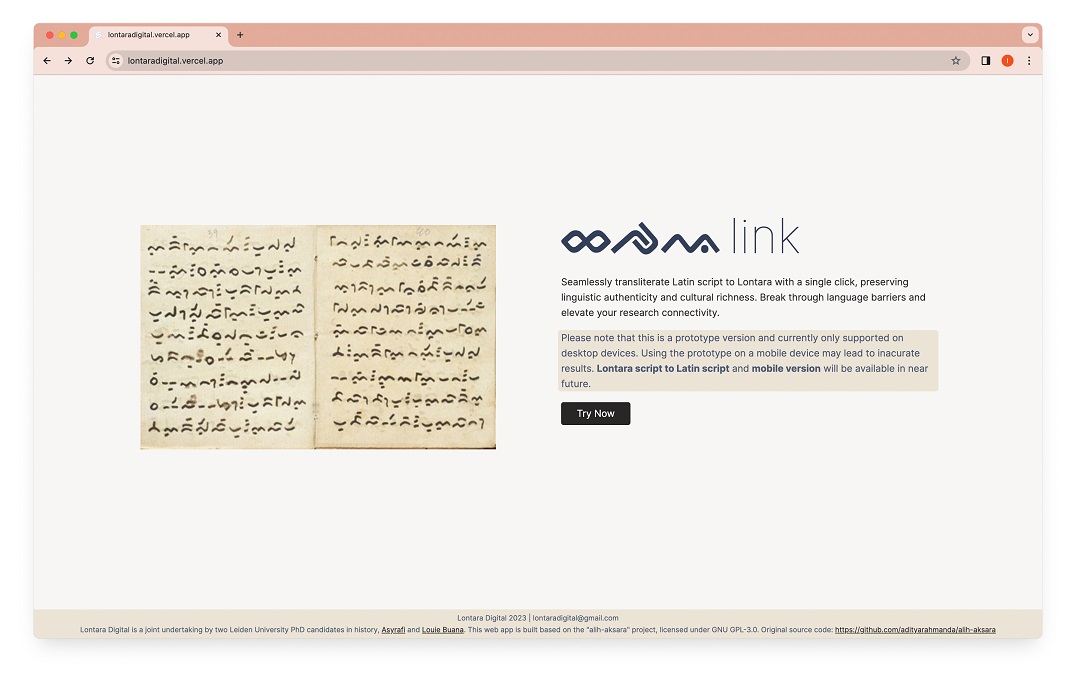
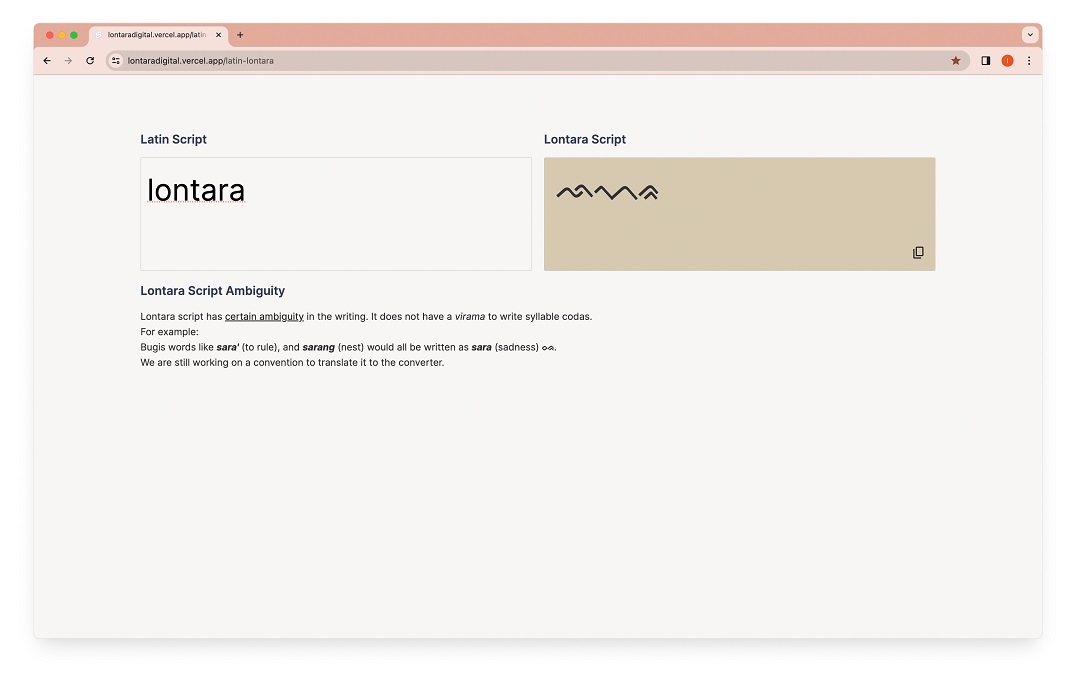
Lontara Digital: Developing Text Recognition Model for Lontara Manuscripts Using Transkribus and PyLaia
Louie Buana & Muhammad Asyrafi
Lontara manuscripts from South Sulawesi have earned a reputation among scholars of Southeast Asian studies for the realistic and open-ended portrayal of the past, in contrast to other local traditions that mix myth and legend with history. In the words of local scholar Abidin (1971), Lontara chronicles record events in a matter-of-fact way, without excessively flattering the rulers, which serves as useful and reliable preliminary sketches for reconstructing history. Among many genres of Lontara manuscripts in South Sulawesi, a local pre-Islamic epic called La Galigo rises to prominence. La Galigo is the world's longest epic (even longer than the Mahabharata) that was acknowledged by UNESCO as Memory of The World for Indonesia and The Netherlands in 2011.
This project aims to provide a tool for the accessibility and literacy of Lontara sources from South Sulawesi through the use of technology. This pilot project will develop a Customised Text Recognition Model prototype for the Lontara script by utilising Transkribus and PyLaia. The project will begin with creating a fresh Ground Truth from the La Galigo manuscripts kept in Leiden University Special Collection.
Ultimately, this project will compile the digitised documents written in Lontara script scattered in libraries and institutions worldwide. By doing this, the project will map, catalogue, and preserve Buginese and Makassarese knowledge and open many research possibilities. In the long run, we attempt to make the Lontara collection searchable using Handwritten Text Recognition (HTR) technology. The expected results from this pilot project, therefore:
- Text Recognition Model for Lontara script;
- Web application for Latin-Lontara and Lontara-Latin transliteration;
- Blog/website to showcase the database of scattered Lontara manuscripts.
The project is also expected to open up opportunities for further exploration of non-Western historical sources in the Leiden University collections through HTR technology. At the time of writing this proposal, there are only five non-western public models available in Transkribus. As a result, the project aims to address the gaps in the non-western script model in Transkribus.

Reading Metaphor in Literary Machine Translation and Post-Editing
Lettie Dorst, Alina Karakanta, Katinka Zeven and Mayra Nas
This project focuses on metaphors in literary machine translation. It investigates what happens to metaphors when literary texts are machine-translated, for example using Google Translate or ChatGPT, and how readers respond to machine-translated metaphors. While a small but growing number of studies has investigated the usefulness of Statistical and Neural Machine Translation for literary translation, obtaining promising results for different genres (short stories, novels, poems) and language pairs (including English-French and English-Spanish), no studies have thus far focused specifically on metaphors and whether the way Machine Translation handles metaphors affects how readers understand and appreciate literary texts. A recent study by Guerberof-Arenas and Toral (2022) suggests that metaphors are likely to require creative solutions in translation, while Machine Translation tends to be direct, producing a literal translation by default. However, we don’t know whether readers interpret unidiomatic or unexpected literally translated metaphors as errors or as creativity.
The project will involve three main activities:
- The first activity involves machine-translating 10 excerpts from English novels into Dutch using an Neural Machine Translation model (Google Translate) and a Large Language Model (ChatGPT).
- For the second activity, the Machine Translation output will be corrected and revised (post-edited) by two professional literary translators to determine which ones they consider incorrect or inappropriate (linguistically, stylistically or culturally) as compared to how a human would translate them.
- Finally, the third activity addresses the reactions of readers when they read literary passages with machine-translated metaphors. An online questionnaire will be used to determine how understandable, readable and enjoyable they are from the readers’ perspective.
Mapping the development of Quranic Reading Traditions (QRTs) with the HAMaLaT-Quran Database (8th–11th centuries CE)
Jeremy Farrell
In the past twenty five years, the field of Quranic Studies has witnessed the wide adoption of computational tools and frameworks of inquiry, which in turn has enabled scholarship on both the literary forms and manuscript tradition of the Quran to shed new light on the history of the sacred scripture and early communities of Muslims. Increasingly, researchers wishing to extend the scale of inquiry have begun applying similar computational tools and frameworks to a vast source of data, the Quranic Reading Traditions: the textually encoded record representing a historical figure's recitation of the entire text of the Quran and which is accepted as valid for ritual purposes. The formulation and subsequent transmission of these Quranic Reading Traditions occurred, over the course of the 7th through 11th centuries CE, through the efforts of an ethnically and economically diverse network of hundreds of actors from across the geographical expanse of the Islamic polity over more than 400 years. With the support of the Leiden University Centre for Digital Humanities, the Historical Atlas of the Mobility, Literature, and Transmission of the Quranic Reading Traditions (HAMaLaT-Quran) project models the available prosopographical data using digital tools, including network analysis (SNA), geographic information systems (GIS), and data visualization libraries. The resulting database will serve as a tool to enable future research to formulate and test precise questions about not only the growth and spread of individual reading traditions, but also the nature of the transmission of culturally vital information within the early Islamic social system.
Biography
Jeremy Farrell is a Postdoctoral Research Scholar at the Leiden University Centre for Linguistics (LUCL), as part of the ERC-Consolidator project entitled QurCan: The Canonization of the Quranic Reading Traditions. His scholarship utilizes text critical and computational methods, focusing on diverse aspects of Islamic society and Arabic literature, particularly the influence of textuality on the transmission of culture.
The Effect of Immersive 360 Tasks on Aspects of L2 Speaking
Nivja de Jong & Paz Gonzalez Gonzalez
Within language learning studies, 360-degree video technology is recognised for providing learners with a realistic and authentic environment. This technology creates immersive content from real-world footage, and fosters a sense of presence and engagement in language learning environments. In prior studies funded by LUCDH projects, speaking tasks utilizing 360-degree techniques were developed to prompt speech for applied linguistic research. Although these techniques were tested in previous projects, a comprehensive evaluation of their effectiveness and outcomes is still pending.
The present project aims to address this research gap by evaluating the effect of using immersive 360 videos as elicitation compared to speech elicited through the same tasks presented in two types of 2D formats: normal 2D videos and cartoons. The comparison involves quantitative measurements of the naturalness of the speech in the three conditions and a qualitative evaluation by students. Because the production and use of speaking tasks with the 360 technique are more expensive than 2D videos or simple cartoons, the outcomes of the research will inform future researchers and language teaching professionals to evaluate the worth of creating 360 videos for speaking tasks in research and teaching.
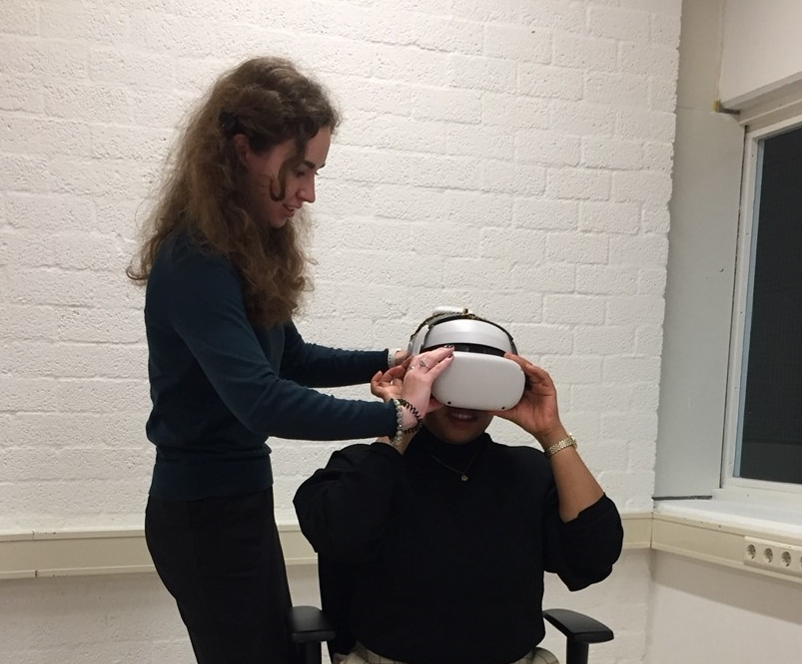
Virtual reality storytelling, embodied experience, empathy and understanding (Correspondents of the World)
Sarita Koendjbiharie
Virtual reality storytelling, embodied experience, empathy and understanding
In his 2015 TED talk Chris Milk touted Virtual Reality as ‘ultimate empathy machine’. Why? Since with this technology, one can viscerally experience anything from another person’s perspective.
VR experiences, or immersive virtual environments (IVEs), are 3D, computer generated environments which enable free movement and interaction with these surroundings by users. In IVEs the perceptual input of the real world is replaced by perceptual input from a virtual world (Herrera et al. 2018).
Researchers have created IVEs for various purposes usually for perspective-taking of stigmatised or marginalised groups of people. For example, ‘the 1000 cut journey’, an IVE in which participants embody a black male, Michael Sterling, experiencing racism as a child, adolescent and adult. Or ‘Carne y Arena’ where one is transported to the Mexican desert to join a caravan of migrants about to cross the United States border with a ‘coyote’ or smuggler.
Evidence on the impact of IVEs on changes in empathy behaviour is however mixed and based mainly on survey data. This study addresses the need for more clarity on user ‘s understanding of the other after walking in their ‘virtual shoes’.
Correspondents of the World is a platform that invites people around the world to tell their stories and share their personal experiences in relation to global issues including gender and sexuality, migration and exile, liberation and human rights. In this study, we create an IVE of such a story location. For example: Black Lives Matter: An Experience in the Train or Gender-neutral Toilets – A Safe Space Taken Away?
In this study the IVE will enable participants to feel the perspective of a character/author depicted in the story through access to the sights and sounds, and even to the feelings and emotions, associated with the personal story.
The IVE enables study of embodied experience i.e. action taken with one’s own body, emotional arousal and its impact on empathy. Insights have been accumulating, there is space however, for more exploratory qualitative research into user experience and empathic arousal after Virtual Reality storytelling, particularly compared to online reading and imagining the context.
Through this research we seek a more nuanced understanding on the impact of Virtual Reality storytelling on users, its strengths and pitfalls including blind morality (Bloom, 2017). We aim to analyse in-depth the extent to which Virtual Reality can foster empathy and enhance better understanding in the world.
Sources
- Milk C. How virtual reality can create the ultimate empathy machine [Internet]. TED: Ideas worth spreading. 2015 [cited 2023Dec13]. How virtual reality can create the ultimate empathy machine (TED)
- Herrera, F., Bailenson, J., Weisz, E., Ogle, E., & Zaki, J. (2018). Building long-term empathy: A large-scale comparison of traditional and virtual reality perspective-taking. PloS one, 13(10), e0204494.
- 1000 cut journey (Cogburn Research Group)
- Carne-y-arena (Virtually present, Physically invisible)
- Black lives matter an experience in the train (CotW)
- Gender neutral toilets a safe space taken away (CotW)
- Bloom, P. (2017). Against empathy: The case for rational compassion. Random House.
Updated text and image (20 Feb 2025)
Over the second half of 2024, Dr. Sarita Koendjbiharie and Vennila Vilvanathan (VR Research Programmer) have developed and completed a virtual reality (VR) environment for researching the elicitation of empathy. This VR environment simulates a real-life experience by Naomi, a female passenger of color in a first class train compartment. Her online written story has been the basis for developing the VR setting. In the final phase, Naomi visited the SSH lab in the Silvius building to experience VR first-hand. She gave constructive feedback used for finetuning the simulation, and encouragingly conveyed her enthusiasm about the outcome. The VR setting is life-like according to her, and the interaction with the train conductor captures importance nuances.
Demos at the opening of the Humanities Hub and Immersive Tech Event also led to feedback used for improvement and insight. The research including data collection through VR experiments, is set to take place in the first half of 2025.

D or t? Using Big Data to Explore Linguistic Factors in Dutch Verb Spelling
Alex Reuneker
Introduction
The rules for Dutch verb conjugation are simple and understandable, yet they remain a stumbling block for both students in secondary and higher education, and for the working population. Previous studies show that errors in verb spelling, even those by skilled writers, are due to factors such as time pressure and frequency-dominance in homophone verbs. For instance, the finite verb verhuist (to move) and the participle verhuisd (has moved) have identical pronunciation, but different orthographies. As the participle verhuisd has a higher frequency of use, it is often used in linguistic contexts that require verhuist. The mainly psycholinguistic approach of existing studies to understand such problems has targeted homophone dominance specifically for its relation to extralinguistic factors such as working memory, highlighting that cognitive pressure may cause fallback from computation to look-up of the most frequent word form in memory. In the literature, however, several intra-linguistic factors are hypothesized to be of influence but remain to be systematically tested.
[Updated: 25 Feb 2025]
The project
As existing research on Dutch verb spelling is often limited to small experimental studies, this project will provide new insights into determinants of verb-spelling errors. As it becomes clear from the recent debate surrounding the declining state of the language proficiency of high-school students, from spelling to reading skills, the time is ripe to add a digital, quantitative perspective to problems in language education. This project explored two suggested, yet unstudied intra-linguistic factors in verb spelling, namely personal vs possessive pronouns (e.g., word je... vs wordt je broer...), and imperative forms (word lid!). Together with the applicant, two student-assistants have investigated these factors by combining their insights in Dutch Linguistics and Digital Humanities onto a new dataset spanning 6 million answers by thousands of users collected through Gespeld.nl.
The results
The resulting studies were completed. One of the resulting papers is in process of finalization, the other has been submitted for review to an academic journal.
Study 1: The spelling of homophonic verbs preceding the reduced possessive and personal pronoun je (Alex Reuneker & Mette Rebel)
As mentioned above, even for the best students in Dutch secondary education, the spelling of homophonic verbs before reduced pronoun je ‘you/your’ remains a problem, as the pronoun may be either the reduced form of personal pronoun jij ‘you’ or of the possessive pronoun jouw ‘your’. Consequently, the spelling of the verb preceding depends on this difference: it gets a final –t or not. For this study, we analysed the legal framework in which Dutch language proficiency is described, we compared teaching methods, and we performed quantitative analyses, such as regressions analyses, on a large set of students’ spellings of verbs to test possible associations between spelling errors in homophonic verbs and the two functions of the reduced pronoun je, taking into account education level, and education stage. The results show that homophonic verbs preceding je ‘you/your’ indeed contain significantly more spelling errors than other homophonic verbs. Accordingly, we have formulated concrete recommendations for the legal framework and methods of Dutch language education.
Study 2: The spelling of the imperative mood in secondary education
‘A peculiar type of finite verb’ is what Van den Toorn (1984: 12) calls the imperative mood. A finite verb is, after all, a verb that agrees with its subject and indicates whether an event or situation is simultaneous with or prior to the moment of speaking. However, in the imperative mood, the subject of the sentence is not expressed, and according to traditional grammar, in Dutch the imperative mood cannot change tense. This study focused on the form of the imperative mood that is identical to the form of the first person singular present tense. In the case of homophone verbs, this form sounds the same as the verb form in third-person singular present tense, but it differs in orthography. In a large-scale data analysis, we compared the errors made in the spelling of the imperative mood with that of regular homophonic fine verbs. We show that Dutch secondary-school students at all levels and in all grades have more difficulty spelling the imperative mood than spelling a regular finite verb. Accordingly, we have offered concrete recommendations for improving education materials.
Conclusion
Using big data, we were able to enhance the academic knowledge of two specific factors in verb-spelling errors and to offer evidence-based solutions to long-lasting and persistent problem in Dutch language education.

Interviews Going Open! Developing Interdisciplinary Guidelines on How to Publish Qualitative Interview Data as Open Data
Naomi Truan
The project “Interviews Going Open! Developing Interdisciplinary Guidelines on How to Publish Qualitative Interview Data as Open Data” aims at making potentially sensitive data used for qualitative purposes suitable for its reuse in Open Access. Using sociolinguistic interviews as an example, we will develop FAIR guidelines and workflows (https://www.go-fair.org/fair-principles/) and apply the framework of the Text Encoding Initiative (https://tei-c.org/) to show how qualitative data may go open.
Small Grants 2023 Research Projects
Setting up Forensic Text Analysis Research
Willemijn Heeren
Authorship analysis techniques chart similarities between texts in sophisticated ways and support the attribution of manuscripts by unknown authors to known authors. These techniques have been developed mostly for large texts, such as book manuscripts. For reliable use in forensics the text features developed for manuscript attribution cannot simply be re-used, because in forensics, features must also provide reliable information in much shorter text types (e.g. e-mails and chat messages). Also, features characteristic of these shorter text types versus features characteristic of their authors need to be sorted out.
To support further research on how different text types that are relevant in forensic contexts convey author information, and on how variation within and between authors is distributed across texts and text types, this project developed a research pipeline that allows for such work. The pipeline consists of components for the preprocessing of various text types, for feature extraction from texts, for feature comparison between texts, and will be extended to include a Bayesian statistical evaluation of the similarities and differences.
Recent developments in forensic speaker comparisons predict that this pipeline can be used for research on different materials as well, namely on speech transcripts used in forensic speaker comparisons. To further develop the quantification of word choice and language performance in speech, recent investigations have shown that a speech transcript contains useful information. Applying authorship analysis techniques to such textual representations of speech, features such as word choice can be quantified in systematic ways, and used to differentiate between individuals.

VR Videos for SLA Research
Paz Gonzalez Gonzalez & Nivja de Jong
Using 360° scenarios as rich stimuli to elicit second language learners’ production data
The optimal elicitation of interlanguage has been a recurring theme in SLA methodology. Studies have been carried out to elicit data from standardized tests, production tasks, mostly written, and also oral data collection has taken place. Lately, Paz González has worked with visual stimuli as tools to elicit specific language data. Nevertheless, her experience is that the carefully developed stimuli (comics, photographs, (see picture)) only provide part of the context: although we can never fully control what the speaker may be thinking about at a given moment, 2D stimuli on paper are very limited, and can be partial and restricted. The current project involves Virtual Reality (VR) scenarios using a 360° environment, as this technique can offer more detailed stimuli.
Presenting language learners with a 360° environment can help us get much closer to a full and natural context; the previous proof of concept aimed to achieve a controlled vivid context for linguistic experiments thanks to VR technology. The goal of the current research proposal is to create even more vivid contexts, learning from the improvements stated in the previous study, and use them to collect L2 data and test the technique for the language learning classroom.
Concretely, we plan to use this methodology to study the acquisition of aspect in Spanish. In which scenarios do learners use ‘caminé’ (I walked), in which ‘caminaba’ (I was walking/would walk) and in which ‘he caminado’ (I have walked)? What are the essential contextual and linguistic factors in the choice between these past verb forms in the interlanguage of the L2 learners? Additionally, we will explore how the VR scenarios can be used in language teaching contexts. For this part, we will present the (adapted) scenarios to language teachers and ask them to advise us on the practicability of using such tasks, which will lead to improving the tasks further for the L2 classroom.


Mapping Ancient Migration
Rens Tacoma
Despite slow travel methods, geographical barriers and social inequalities, individuals living in the Hellenistic and Roman era are thought to have been quite mobile. This is the consensus that historians have come to since the “mobility turn” of the social sciences took root in ancient historiography from the 1990s onward. Recent years have seen projects improving our knowledge of Graeco-Roman mobility. One important source is formed by inscriptions. Usually they consist of small tombstones in which the origin of the deceased is recorded. Historians have begun to explore their potential, discussing not only the data they contain, but also the biases of the material, and the issue of self-representation.
Funerary epigrams offer an invaluable but understudied source in this regard. These inscriptions, written in verse, are usually longer and provide more details than prose epitaphs. Their interpretation is not straightforward, but they allow for a nuanced study of ancient mobility. Their potential has been explored before, in particular in an upcoming book co-authored by the project leader. The dataset of this monograph provides us with roughly 150 epigrams that mention mobility. Similarly, an on-going research traineeship program on Greek epigrams from Rome – involving the project leader and the student who will carry out this Small Grant project – provides a second, smaller dataset. Our project will use QGIS to map the migration patterns of the individuals mentioned in the epigrams of these two datasets.
As such, this project has three related goals. The first and most concrete goal is the visualization of migration patterns in Greek epigrams from the Greek East dating to Hellenistic and Roman times. In this way we can analyze changes over time, compare the mobility patterns of males and females, and contrast the movement of elites with that of non-elites. The second goal is to apply the same methodology to the epigrams from Rome. The third and main goal follows directly from the first two. It is the development of an efficient method that is also applicable to other datasets and that can be used by other scholars.
Overall, digital tools to visualize the data will not only help to illustrate the arguments made in more traditional qualitative and textual analyses, but actually provide a method for further study.

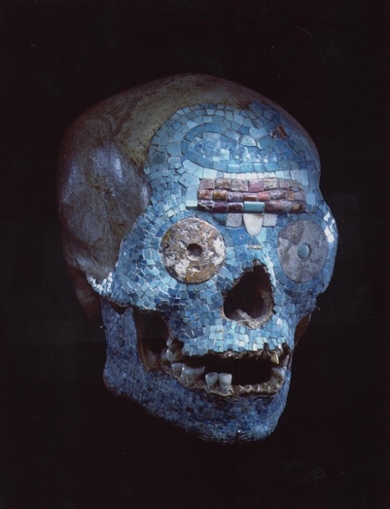
3D Reproduction Methods in Contested Heritage
Liselore Tissen
In 1963, the Volkenkunde museum in Leiden, the Netherlands, acquired a Mesoamerican human skull covered with mosaic. Although research, proved its composition to be a forgery, it does contain an ancestral human skull that was taken and commodified as Mexican curios. This is not an exception there are many cases of cultural dispossession that indigenous communities have been subjected to.
The discussion about the repatriation and restitution of stolen or looted artifacts has been a growing topic of interest within the humanities and museums. Museums are hesitant when it comes to restitution requests and claims of their objects. One argument is that, evidently, there is only one authentic artifact. Returning the requested artifact might mean losing a precious and important object of the collection, however, for communities of origin it means the return of a piece of their culture. Unfortunately, this oftentimes results in an uneven conversation as the communities of origin are oftentimes not consulted within the decision-making process (e.g. the repatriation of Naturalis’ Java Man to Indonesia). A solution to find a compromise for these two different perspectives has not yet been provided.
Yet, recent developments in the digital and technological field might provide a solution to this ethical debate. 3D printing specifically has made it possible to create almost identical copies of any artifact. Furthermore, because the 3D model necessary to fabricate an object can be manipulated digitally (e.g. by enlarging sections) and disclosed unlimitedly, an artifact can be shown in a variety of ways, igniting new ways of interpreting and engaging with original artifacts.
This project aims to use the Mixtec skull as a case study explore the applicability of 3D printing and scanning to negotiate issues surrounding contested heritage in museums in a co-creative way.
Small Grants 2022 Research Projects
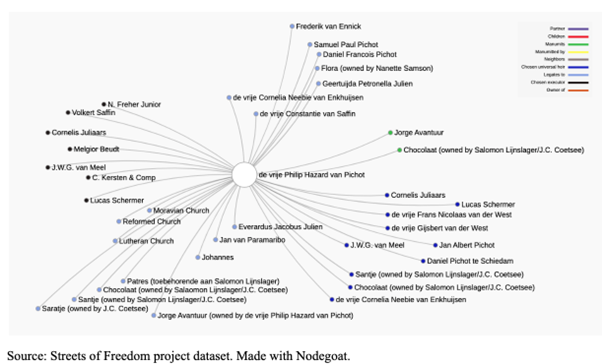
Streets of Freedom? Mapping enslaved lifeways and urban emancipation
Karwan Fatah-Black and Ramona Negrón
Across history, communities have managed to overcome hardship and marginalization, but scholars often take an outside view of such developments. Post-slavery and emancipation studies deal with issues on the disciplinary boundaries of social science, economics, and history. The growing number of digitized collections of serial archival material enables a cross-pollination between statistical analysis of economic development and the stories of colonial lifeways. This allows us to come very close to actual processes of emancipation, and trace developments over generations. Digital research methods are greatly opening up the ability to uncover subaltern lives and strategies and how marginalized people found ways to freedom and emancipation. Using the abundance of data available for Suriname we wish to do a proof of concept for reconstructing emancipatory networks and explore their spatial dimension.
In this study we use landownership as a proxy for emancipation. Landownership is both predicated on access to capital and access to institutions that protect property rights. Data on landownership is widely available in the colonial archive. By using serial data on manumission, land ownership, and family ties in the city of Paramaribo we will reconstruct the ties that formed the social networks that enabled intergenerational emancipation and map the urban communities of freedmen.
Dynamic Measures of L2 Speaking
Nivja de Jong
Dynamic measures of speaking
In second language (L2) acquisition research, measures of linguistic aspects of speaking performances are used to track L2 development. As L2 learners progress in their development from beginner to advanced speaker, they will use more diverse language in terms of vocabulary and syntactic patterns, and do so more fluently, in terms of speech rate and pausing. In L2 research as well as L2 assessment, currently, these linguistic aspects are measured statically. For instance, speech rate of a performance is calculated on the basis of total number of syllables and total time in a speaking performance. However, speaking is a dynamic process in which speakers constantly go through several stages of speaking. For research on L2 development and assessment, this means that a lot of information is lost by only considering static measures without the information on the changes of these aspects throughout a task.
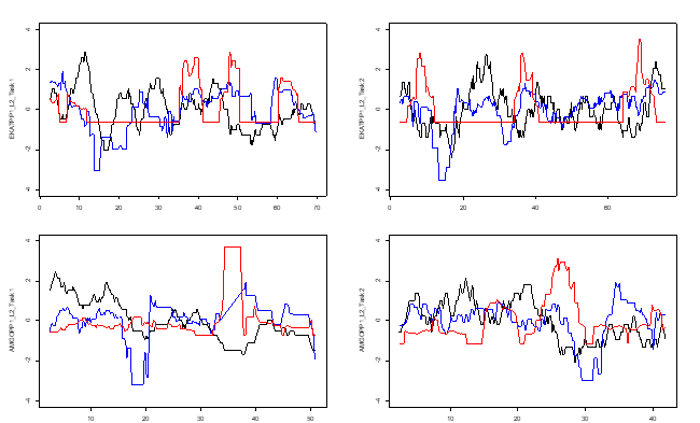
In this project we have developed a convenient procedure for researchers to measure dynamicity of aspects in (L2) speech. The procedure is as follows: after verbatim transcription of a speaking performance, the researchers aligns this transcript to the speech (e.g., using Webmaus). Following, a newly-developed praat-script is run, that combines python and praat to code lexical complexity and fluency measures and outputs a table with the measures averaged over windows of for instance 5 seconds, with .2 seconds time-steps.
The figure below shows how for two L2 English participants, in two different speaking tasks, three (scaled) measures (y-axis, in SD’s) fluctuate differently through time (x-axis, in seconds), measured in windows of 5 seconds, with .2 seconds timesteps (red: syllables; black: filled pauses; blue: corpus word frequency).
Historical Social Network Analysis of European Elites
Anne-Isabelle Richard
European institutions (Council of Europe, European Community of Coal and Steel) were being created from the late 1940s onwards. This was an endeavour initiated by civil society actors united in the European Movement, as much as it was driven by state actors. These actors were acutely aware that the newly established European institutions needed to be staffed and that if the European venture were to succeed, an elite needed to be trained. For this purpose, the College of Europe in Bruges and the Centre Européen Universitaire in Nancy were founded in 1949 and 1950, respectively.
In the years since their founding, these institutions have attracted students from across Europe, including from behind the Iron Curtain, as well as the United States and the (former) colonies. Many alumni went on to positions in the European institutions. However, they also went on to positions of influence, if not power, in national spheres as well as academia and business.
To understand the influence of the ‘European’ education they received this project will perform a historical social network analysis on the alumni from both institutions in the years up to 1970. This project is a first step toward a larger project analysing the formation of elites, at the intersection of the Global North and the Global South. Besides analysing the social networks of the students at these European universities, the aim of the project is to develop a protocol that is well suited for this kind of study based on material that
- addresses actors from both the Global North and South
- is mostly in the public domain (archives, secondary sources, internet)
The software I will use is Gephi. This is a free, open source, frequently used software for historical social network analysis.

VR for Linguistic Fieldwork
Jenneke Van der Wal and Paz Gonzalez Gonzalez
In this proof-of-concept project, we employed Virtual Reality (VR) technology for linguistic data collection.
Gathering linguistic data on various languages is essential for linguistic research. For both theoretical and applied linguists it is important to get the right data to test hypotheses. In order to achieve this, the speakers of the language under study must judge and produce utterances in the right context. For example, speakers of Spanish have to choose between ‘caminé’ (I walked), ‘caminaba’ (I was walking/would walk), and ‘he caminado’ (I have walked). If we want to know how speakers of Argentinian vs Castillian Spanish choose between these verb forms, we need to tease apart the relevant contextual and linguistic factors. Traditional verbal and picture stimuli on paper are quite restricted: we can never fully control what the speaker may be imagining in addition to the given stimulus. We can get much closer to a full and natural context if we present speakers with a 360° vivid environment; one in which the linguistic factors to be studied are carefully controlled. This is now possible thanks to VR technology.
We piloted the technology by creating 360° virtual environments in 4 videos, and tested these with speakers of Spanish to study linguistic Aspect, and with speakers of Xitsonga/Xichangana to study Focus and Evidentiality. The participants indicated that ‘It was as if I was there’ and commented ‘I loved the experience, it is fascinating the idea that you more or less enter their space’. While we have no comparison yet between 3D and 2D stimuli, the first results are very promising.
See also the blogpost Irina Morozova wrote about our project!
VR team: Jenneke van der Wal, Paz González, Claudia Berruti, Victor van Doorn, Irina Morozova, Jai von Raesfeld Meyer, Thomas Vorisek
-

Stills from the Focus/evidentiality subproject videos: when answering the question ‘what are they sawing?’, does it matter whether you witness the action directly or not? -

Stills from the Focus/evidentiality subproject videos: when answering the question ‘what are they sawing?’, does it matter whether you witness the action directly or not? -

Stills from the Aspect subproject videos: -

Stills from the Aspect subproject videos: -

From the data collection: -
From the data collection:
Health Information Accessibility in Migrant Communities: A case for machine translation literacy
Susana Valdez and Ana Guerberof-Arenas
The importance of equal access to health information ranks high in the UN's key global issues. When patients cannot find the information in a language they can understand, they often turn to online machine translation (MT), such as Google Translate or DeepL.
The technology is easily accessible, apparently simple to use, and (mostly) free. However, users might not be aware of the pitfalls of using this technology. For instance, when using this automated translation to understand doctors’ advice on how to take a particular medicine, a user might be misled into believing a higher level of accuracy, which poses potential high risks to their health. In the context of the COVID-19 pandemic, the impact of MT and the implementation of MT literacy have come even more to the fore. MT was considered a vital resource for a rapid-response infrastructure allowing fast dissemination of information into a high number of languages.
MT literacy in healthcare contexts is hence essential. This comprehends acquiring knowledge of how MT works, understanding how to use it safely and ethically, and how to interpret the output accurately.
Aim of the project
Our research focuses on understanding how migrant communities living in the Netherlands use MT in health contexts. In this project, this will be done by collecting data through questionnaires and vignettes on when, how and why, and with what challenges MT is used by non-Dutch speakers. This is expected to serve as a proof of concept to build training material for this community.
(Begin updated text 12 Jan 2023)

With and for migrant communities
This project actively involves members of these communities in the research process. Grounded in a participatory worldview, we seek to engage and empower migrant communities throughout this project. We will not be conducting research on the target communities but with and for them. Ultimately, our project aims to have an effective and meaningful impact on communities through empowerment and personal and social growth. Furthermore, our research project will hopefully represent a stepping stone to a larger project that will focus on creating practical knowledge that supports an informed and critical use of digital resources, thus improving the overall well-being and integration of the target communities in the Netherlands.
Preliminary findings
A preliminary analysis of the questionnaire provides new insights about the use of MT in health contexts. Some non-native speakers of Dutch use MT in health-related contexts, especially in situations that do not require face-to-face interaction. For instance, most participants use MT to understand a letter sent by a doctor or the RIVM by scanning the document with the camera phone or typing directly in the mobile app. In face-to-face situations – for instance, in medical appointments or emergency rooms – MT is not the most common strategy. For those that do use MT in face-to-face interactions, besides typing directly on the phone app, another common strategy is to use MT when preparing what to say beforehand.
The main identified challenges when using MT in health-related contexts include:
● perception of incorrect or inaccurate translations
● not trusting MT
● not understanding the translation even when MT seems good enough
● considering it a time-consuming process not ideal for face-to-face interactions
● feeling insecure or vulnerable in these situations
The vignette-based interviews allowed us to collect qualitative data that wouldn’t be possible otherwise. The vignette method is commonly used in social sciences, but, unfortunately, has attracted very little attention from Translation and Interpreting scholars. We wanted to use this opportunity also to explore this method and apply it to this study. The vignette technique makes use of a short fictional scenario or short story with the intent of eliciting perceptions, opinions and beliefs to typical scenarios with the aim of clarifying participants’ decision-making processes and allowing for the exploration of actions in context.

First stage of the short story of the vignette-based interview
The preliminary analysis of the interview data showed that the fictional scenario we designed was highly relatable for most interviewees. They identified themselves with the main character, a non-Dutch speaker that had moved to the Netherlands amid the pandemic and had a rudimentary knowledge of Dutch. Throughout the short story we presented, participants recommended two main strategies to deal with medical information: to use MT and to ask neighbours or family to translate the information. Most interviewees welcomed the opportunity to share their views on using MT in health contexts. They reflected on the relationship between trust and decision-making in health contexts: Should I trust the MT output? What are the possible consequences of making health-related decisions based on MT? Am I at risk of significant harm? What happens with my data? Some discussed the dependence on this type of technology in terms of vulnerability. The interviews also showed that some participants struggle with MT and, therefore, there is a need to train migrants on how to use MT. For instance, some interviewees reported not being familiar with some tool features, while others had questions about data privacy. (End updated text 12 Jan 2023)
Small Grants 2021 Research Projects
Mapping the Renaissance Battle for Rome
Susanna de Beer
Rome may or may not be dead, long live Rome! While Renaissance humanist poets battled over what, exactly, ancient Rome meant, and whether or not she had even survived the ages at all: they could at least agree that Rome did offer a legacy that was fruitful to all of them. Serving their widely diverging political, religious, and personal interests, humanist poets used ancient Rome as a metaphorical excavation site from which all kinds of competing images could be extracted in pursuance of prestige, political legitimization, and identity formation. Be it Aurelio Brandolini in Italy, Joachim Du Bellay in France, or Conrad Celtis in Germany: they all appealed to an idea of Rome that suited their respective purposes. In my monograph The Renaissance Battle for Rome I identify and analyse a great variety of images of Rome as they appear in humanist poets’ texts, sketching the outlines of their overarching appropriative strategies.
To visualise the book’s analyses and to facilitate further exploration, I have created an online appendix in the form of a database, to allow for the dynamic presentation of diverse and multi-layered information networks. This project aims to turn the database into a publicly available, interactive website, with an attractive lay-out and intuitive navigation. It will make available the ancient and Renaissance text sources I have used in the book, annotated and cross-referenced to ease user engagement. Many of these texts are not currently easily found online, or, in some cases, published outside of manuscript form at all; they are offered both in their original Latin and in an English translation, to ensure accessibility to a wide public.
My earlier website De Vereeuwigde Stad is based on a similar interactive database in which ancient texts were cross-referenced, but using a relatively limited number of closely defined categories. For the present project, the connections between texts are often more elusive and subjective, ranging from literary templates (like ‘a visit to Rome’) to stereotypical images of Rome (like ‘Rome as city of decadence’). Visualizing these helps to lay bare previously unseen connections, but in order to present complex material sensibly, strategies must be advanced purposefully with user requirements in mind. It is these strategies which this project seeks to design.
Until now, images of Rome have mostly been studied in their immediate contexts and from the confined perspective of particular disciplines, fragmentizing our understanding of the interaction between Renaissance poets and the ancient material they so famously laid claim to. This project will ultimately make possible innovative multidisciplinary collaboration between scholars from different fields, by making visible analogous imagery across languages and in different media. Going forward, the nature of a database will allow for smooth expansion as will fit scholar and student purposes. I envisage this website as a pilot project to develop ‘Mapping the Renaissance Battle for Rome’ into a larger collaborative and multidisciplinary research project in the future.


Automatic Mapping of Villages and Warriors on 17th and 18th Century Java through the Records of the East India Company
Simon Kemper
The recent years saw major advancements in Handwritten Text Recognition (HTR) and the large-scale digitisation of early modern archives. One of the most fascinating developments has been the highly accurate text recognition of the over-a-million digitised Dutch East India Company (VOC) pages in the Hague and Jakarta. This project aims to explore how Named Entity (NE) processing can be applied to automatically extract person and place names from these archives. The project focuses on the so-called West Monconegoro which lay just beyond the VOC’s administration and at the fringe of the Javanese Mataram realm. Within the Dutch archives, this province is mainly discussed during several major wars occurring on the island between 1677-1682, 1704-1708, 1719-1723, 1741-1743 and 1749-1757.
The event-related nature of the references to West Monconegoro make it interesting to explore how during each of these time frames the types of entities mentioned differed. Scholars have long ignored the places of and persons from West Monconegoro as they were deemed peripheral to the VOC trade posts and the Javanese central courts alike. Their obscurity can be overcome by linking the names of villages to those of the historical regions and provinces of which they were part, and by tying the names of persons to local genealogies. In this way, the place and person entities can be successfully added to knowledge graphs (KGs) in large numbers.
The National Archives of the Netherlands has already conducted minimally supervised Named Entity Recognition (NER) based on three general tags—person, date and location—representing entity types on 4439 random pages from the archives of the VOC chamber in Zeeland (see velehanden.nl). This effort relies on a basic placename database which has mainly been compiled from records concerning the VOC ports. As such, the entity linking largely ignores the many villages and hinterland regions which occur within the VOC archives, nor pays particular attention to Asian names. Therefore, the important foundation laid by the National Archive deserves to be delved into further through populating the KGs with vernacular entities and using probabilistic indexing to tag such entities in larger numbers.
This project will add hundreds of entity pages on rural villages and regencies from West Monconegoro to Wikidata and the World Historical Gazetteer (WHG) to create a semantic web of linked data which will offer guidance to a BERT-based pre-training and fine-tuning. Furthermore, it will improve the retrieval of entities by linking Wikidata and WHG to the Atlas of Mutual Heritage. In its turn, this digital atlas of VOC maps and itineraries will display all references to placenames via canonical hyperlinks to the appropriate pages of the VOC archives in Jakarta and the Hague.
These links will also associate person entities with places. This last exercise will lay the bedrock for future spatial analyses connecting the places mentioned in the VOC sources with other related phenomena ranging from volcanic eruptions, deforestation, wars, markets, slavery and shipping networks. The research does, therefore, not only improve the transparency of the archives, but also helps create a foundation for follow-up geographic research of the VOC archive using more advanced Natural Language Processing (NLP) tools which also consider syntax.

Mapping Religious Radicalism in 18th-Century Europe
Lionel Laborie
The ‘long’ eighteenth century is generally associated in the collective mind with the Enlightenment, the birth of modernity, religious tolerance, the rise of capitalism, scientific and social progress. Yet the ‘Age of Reason’ was also an Age of Faith marked by episodes of violence and replete with radical dissenters. Most of these movements faced persecution and were driven underground. They did not leave centralised archives and have been largely forgotten, as a result.
My project seeks to shed light on these little-known and often misunderstood groups through the case study on the notorious Camisards or “French Prophets”, a millenarian movement who sparked much controversy in the early eighteenth century. The group attracted Huguenots, Anglicans, Philadelphians, Presbyterians, Quakers, Baptists, Quietists, Roman Catholics and Jews alike. Together, they launched missions across Europe and North America in preparation for Christ’s Second Coming, and formed for decades an underground, transnational network over seven countries that lay the foundations for the Great Evangelical Awakening.
This small digital grant supports the publication of their biographical and prosopographical data on FactGrid, a Wikibase installation designed for historians by the Gotha Research Centre of the University of Erfurt conjointly with Wikimedia Germany. FactGrid’s visualisation tools will help us better understand who their followers were, how they communicated, financed their missions and publications. More generally, investigating the inner workings of such a well-connected movement offers insight into the production and circulation of radical beliefs and ideas against the backdrop of the Enlightenment and help paint a more complete picture of the religious landscape of the eighteenth century.

Developing an Intelligent Metrical Analysis Tool for Latin Poetry
Matthew Payne and Antje Wessels
Automated scansion of poetry by computer is a long-standing goal, and a difficult task. Antje Wessels and Matthew Payne (Classics) and Luuk Nolden and Philippe Bors (Computer Science), who have developed a digital platform specifically for Classical fragments (oscc.lucdh.nl), now plan the implementation of a digital tool to automatically scan Latin poetry. They plan to utilize machine learning to bring a more sophisticated approach which plays to the strengths of artificial intelligence.
Why is the study of meter important?
The sound of a text is an essential part of its content. Similar to what we experience when we listen to different musical styles, our perception of a text depends on the rhythmical patterns in which this text is presented. Different rhythms lead to different expectations about its content, and across literatures and cultures specific rhythms have always been associated with specific genres. This was as true in the ancient world as in the modern. Just as we expect something very different from hearing the rhythms of slam poetry than those of a limerick or from those of a ballad, so an ancient audience would have instantly recognized a line of the epic writer Ennius from a speech of a slave in Plautine comedy - and the Roman writer Cicero tells us that his fellow Romans were sensitive enough to the meanings of rhythms that they could instantly sense when a writer was subverting expectations through his use of metrical patterns.
Why Latin poetry?
Latin poetry features a variety of authors and works which use a wide range of different poetic meters. Actually, rhythm was everywhere in Roman literature, even in prose it was employed as a crucial element: As masters of rhetoric such as Cicero stressed, rhythm, though it should be used subtly, is one of the qualities of good speeches. In Latin poetry different poetic meters - different arrangements of rhythmic patterns - marked out different genres, although the principles of how the sounds of poetry created rhythms remained the same. So Latin poetry provides a large amount of different material written in different poetic meters. Moreover, some of these meters featured simpler rhythms with less metrical variation, others far more complex rhythms with lots of variation. This makes them an excellent set of data for developing a complex scansion tool.
What tools from the digital humanities will you use?
Because Latin poetry contains lots of different meters, it is more important to understand the principles by which the sounds of words create the rhythms than any specific patterns that may only work for one author or work. Just like a student needs to learn to apply these principles and to get a feeling for the relationship between these principles and how they work in practice in texts, so too for automatic scansion to succeed, the machine needs to be able to translate between these fundamental principles and specific metrical patterns as they are found in different authors and genres. This is why we will utilize approaches from machine learning, rather than trying to create a model that follows rules which only work for one kind of metrical pattern. Our current plan is to create a model which can train itself using techniques such as Markov chains and SVM, in order that it be able to handle metrical ambiguities and exceptions. In this way the model should even be able to handle a completely new kind of meter.
How will you go about this?
Just like we teach a student first how to scan more straightforward metrical lines like the dactylic hexameter before going on to rather complex metrical forms such as found in the odes of Horace or in the polymetrical cantica of Plautus, we are going to train our machine on the corpora of Virgil (written in dactylic hexameter), then introduce a different meter, iambic trimeter, found in the tragedies of Seneca, before finally training the model on the more complex metrical forms of Plautus.
What are some interesting applications?
Not all Latin poetry survives to us as complete texts - many lines come to us in the form of fragments, because we find them as quotations in prose texts. Fragments are typically preserved in incomplete metrical units, such as half-lines. They are also more vulnerable to textual corruption, because they were quite likely to be misunderstood or confused with the prose text they were quoted within. One exciting possibility is that the model will help us to better identify the metrical pattern of a corrupt line.
Even more exciting is the possibility of using the model to detect new fragments. There are many prose texts which scholars believe may embed verse lines, but it is difficult and time-consuming for an individual to look through all of them. Applying the model to these texts could flag passages which seem to embed such lines.
What relevance does this have beyond Latin poetry?
A model trained to successfully recognize and extrapolate rhythmic information from texts written in Latin could likely be adapted to work in any language. The adaptation might involve changing the model from analyzing quantity (as in Latin) to analyzing stress (as, for instance, in most Dutch or English poetry), but, while a rules-based approach would require starting from scratch, the machine learning approach could accommodate this.
Who will benefit from this project?
Any student of Latin poetry, at whatever level, who is trying to get a better understanding of metre and its relevance to the content of poetry will gain from applying the model to the texts they are learning about. Rather than seeing scansion as a mechanistic process of applying rules, by experimenting with the scansion tool they will hopefully gain greater insight into the possibilities and complexities of different metres.
As we said at the beginning, the sound of a text is an essential part of its content. By applying machine learning techniques to this problem of metre through the large and multi-faceted body of data provided by Latin poetry we aim to test their usefulness and extensibility. And we hope that any researchers in the humanities who are working on topics where sound is connected with meaning will benefit from our exploration of developing a model through machine learning.

Small Grants 2020 Research Projects
Editing Protagoras
Tazuko van Berkel
“Man is the measure of things.”
“Of gods I cannot say if they exist or not.”
“I’ll teach you good council and citizenship.”
The 5th-century BC Greek intellectual Protagoras has had a profound impact on the Western philosophical canon. Thinkers ranging from Plato and Sextus Empiricus to John Dewey, Marsilio Ficino, Karl Popper and Leo Strauss felt challenged by his radical ideas and engaged with them. The paradox is that all his works are lost to us: whatever the extent of his original written work may have been, they have already been lost shortly after Protagoras’ death. What we are left with are literary and philosophical representations of the person Protagoras, his thought and his (alleged) works.
“Editing Protagoras” is part of an international research project (Protagoras: Sources, Echoes and Interactions) that prepares a dynamic digital edition with commentary and translation of sources of the ancient Greek philosopher Protagoras (5th century BC). Traditional editions of ‘Protagoras’ have focused on ‘fragments’, i.e. on reconstructing an ‘original’ text segment notionally underlying the ‘distorted’ versions ‘quoted’ by later authors. Recent scholarship establishes that this is not a feasible strategy: all we have are reflections and refractions of Protagorean ideas in later sources, sources that are subject to mechanisms of polemics, intertextuality and other forms of text reuse that imply a more active interaction of “cover text” and “target text”. The best way to present such a network of receptions, interpretations and appropriations is by way of a dynamic digital edition.
The overarching project aims to provide an innovative type of source edition that does justice to:
- the nature of an “indirect tradition corpus”, accounting for mechanisms of intertextuality, text reuse, polemics and hermeneutics; instead of postulating problematic categories such as “fragments” and “testimonies”, it visualizes relations between “cover text” and “target text”, analyzing relations between citing authors and quoted texts;
- mechanisms of information management in antiquity: instead of the problematic classical philological Apparatus Fontium (a technical and underanalyzed statement of relations between texts), it will show different kinds of relations (verbal, thematic, chronological) between texts;
- the provisional and reconstructed nature of our sources and our interpretations of them: digital editions ought to show not only research results but also how these results are constructed; they need to make controversies, ambiguities and provisionalities visible.
Such an edition requires a complex database. The aim of the current project, “Editing Protagoras”, is to develop an editor (Alexander) tailormade for such a data architecture, that enables collaborators from all over the world to contribute to this edition project, in a way that is:
- user-friendly (due to its intuitive UI),
- communicative and efficient (workflow-management),
- controlled and transparent (built-in systems of version control, peer review and workflow-hierarchy).
Thus, Alexander, combining the advantages of crowdsourcing and integration of teaching and research, facilitates international collaboration between scholars from Leiden and all over the world, and allows students to participate in this collaboration, making sure that scholarly standards are met.
The LUCDH Small Grant will enable me and student assistant Mees Gelein to develop earlier prototypes of Alexander into a fully operational editor geared to the complex data architecture of the edition project. Once Alexander is in a workable state, it will be possible to aggregate the database content that has been prepared over the past few years by scholars from all over the world. Moreover, the editor itself, tailormade for the construction of complex databases, may have innovative potential as well in setting a new standard for collaborative digital editing projects.

Modeling the Art Historical Canon
Laura Bertens
This project concerns the use of dynamic, visual modelling tools for the understanding of the art historical canon. There is a long tradition of visually representing the canon, in schematic overviews and diagrams. This is indicative of the desire for scientific, ‘objective’ knowledge of the kind produced in the natural sciences. These diagrams will, however, always retain an element of subjectivity and the modelling methods influence our understanding of the represented information. In recent years (visual) modelling techniques for art historical data have been extended to include digital, computational tools, alongside the hand drawn, static diagrams of textbooks. These tools significantly increase modelling strength and functionality. As such, they might be used to help amend the very problem caused by the ‘neutral’ modelling of art historical information. This project proposes to study the use of digital tools in art historical research and education, in order to draw attention to the artificial nature of the static models that art historians are presented with in textbooks and lectures.
In order to study the use of social network analysis and ontological modelling, I will take as a starting point two case studies: the translation of simple diagrams like the one by Ferdinand Olivier (below top figure) using Visone, and the translation of the famous model by Alfred Barr (below bottom figure) using Protégé Ontology Editor. Modelling a set of data is no neutral endeavour; the decisions we take reflect assumptions we hold, either knowingly or without being aware, about the data. Furthermore, methods we choose to model the data come with their own functionalities, biases and restrictions. Taking a closer look at the properties of some of these models, rather than merely at the represented information, will therefore help us understand the mediation that takes place when we translate art historical knowledge into schematic representations.
The main focus of the research project will be an investigation of the uses of the two modelling methods for the purpose of deconstructing the art historical canon. This will take into account feminist critiques of the canon, as for instance discussed by Griselda Pollock (in Differencing the canon, 1999) and Cynthia Freeland (in Art theory, 2003). In addition to this, the project contains an educational component, aimed at introducing methods from digital humanities in the curriculum of the BA Art History (and in particular the track Arts, Media and Society), in order to make both students and colleagues aware of current developments and research possibilities. This will take the form of a workshop, in which the problematic nature of representations of the canon will be discussed and the two methods will be introduced through hands-on tutorials. A trial version of this tutorial has been successfully organized last year and I would like to be able to expand upon that first attempt in years to come. In creating more awareness of the potential of digital humanities for the field of Art History, I hope to be able to set up collaborations with colleagues in my program in this direction.


A 3D Record of the Past: Developing a Volumetric 3D GIS Methodology for Documenting Archaeological Excavations in Three Dimensions; sharing award with Maria Hadjigavriel: Connecting the Pieces: Employing 3D Modelling to Reconstruct Archaeological Artefacts and Contexts
Marina Gavryushkina
This combined project focuses on the use of 3D modeling techniques for the documentation and analysis of archaeological excavations. This study will focus on the digital reconstruction of contexts from Chlorakas-Palloures, a Chalcolithic settlement in Cyprus (ca. 3000-2400 BC), currently excavated by Leiden University: www.palloures.eu.
The first portion of this investigation deals with developing a workflow of capturing 3D spatial data during excavation, and addresses the methodological challenges of volumetric modeling of archaeological stratigraphy using open source and cost-effective methodologies. The goal is to generate a 3D record of all features uncovered during excavation, which can be used to allow users to zoom in and pan around the model to better understand patterns within the site stratigraphy.
The second part focuses on one specific context, a building with a large concentration of big storage vessels within multiple layers. A parallel of this context is the Pithos House, from Kissonerga-Mosphilia, which contained large vessels and other artefacts. The dense concentration of certain artefacts has been associated with the redistribution of surplus of agricultural products, and social differentiations. Photogrammetry and 3D GIS will be applied on each layer during the excavation to create 3D models of the layers and the individual pottery sherds, in order to reconstruct the vessels and how they were situated within the building. This part of the project aims to develop a workflow which will enable and facilitate the excavation of in-situ artefacts, as well as the understanding of the relations within their context.
Ultimately, this project will yield a better understanding of archaeological contexts and will allow for an immersive experience of on-going interpretations. Additionally, this study aims to make it possible to publish archaeological excavation data as interactive 3D models to encourage inter-disciplinary cooperation and make cultural heritage data more widely available to the public.
Participant Database for Infant and Child Research
Andreea Geambașu
This project aims to create a safe, secure, GDPR-compliant, and user-friendly online participant database, necessary for the recruitment of infant research participants. This project has the potential to have a high impact on infant research.
Mobilizing metadata: Open Data Kit for Linguistic Fieldwork
Richard T. Griscom
Linguistic fieldworkers collect and archive metadata but often work in resource-constrained environments that prevent them from using computers to enter data directly. In such situations, linguists must complete time-consuming and error-prone digitization tasks that limit the quantity and quality of their research outputs. This project aims to develop a method for entering linguistic metadata into mobile devices using the Open Data Kit (ODK) platform, a suite of tools designed for mobile data entry, together with the IMDI linguistic metadata standards developed by the Max Planck Institute (MPI).
Open Data Kit is a free and open-source software platform for collecting and managing data in resource-constrained environments, and it includes three primary applications: ODK Build, a web application for creating custom forms for data entry based on the XForm standard, ODK Aggregate, a Java server application to store, analyze, and export form data, and ODK Collect, an Android application that allows for the entry of data directly into mobile devices. With all three of these components working together, teams of researchers can collect data quickly and simultaneously in remote areas, and all of their data can be compiled together on a single server.
A second goal of the project is to implement the ODK method in the field and to critically analyze its impact on the process and output of linguistic fieldwork. The method will be implemented in two projects which are funded by the Endangered Languages Documentation Programme (ELDP) and include five two-person teams of local researchers from the Hadza and Ihanzu speech communities of Tanzania in East Africa. The scale of the two coordinated documentation projects and the remote fieldwork conditions of northern Tanzania together make for a unique opportunity to put the ODK metadata method to the test. Each team of local researchers will be given an Android device with ODK Collect installed and they will receive training on how to use the software to enter metadata. After collecting data for a period of at least two months, researchers will then be interviewed about their experience using the ODK linguistic metadata method, and a report analyzing the impact of the method on the fieldwork process and its implications for research reproducibility and archiving will be submitted for publication.
Integration of Digital Imaging Technology in Thesis Performance and Exhibition
k.g. Guttman
Visiting Hours 2
My theoretical and artistic research examines how, in site-situated events, intertwining concepts of territoriality, hospitality, and choreography produce new practices and embodied ways of knowing.
Both the terms territoriality and choreography are critical concepts and practices that explore navigation and inventions of space and time, question state space and social relations, and privilege concerns for perception and inhabitation of a site. Aspects that are explored include the study of Western spatial discourses, boundaries and enclosures, ownership, authorship, and an interrogation of the Western conception of sovereign identity. Choreographic study focuses on the history of sense perception in the West, somatic research, and how processes of corporeal attention may be crafted.
The exhibition integrates a digital new media technique to explore territoriality and choreography.
The open source technology OBS (Open Broadcaster Software) is an open source, online platform that allows for direct streaming/mixing of actual live green-screen space and new media materials (images or videos). As such, the platform provides an invaluable technique for live performance and exhibition events to include archival or contemporary images, to « enter into them », to consider images as sites for interacting.


Spaces of Awareness and Criminality in the Past
Marion Pluskota
This project aims at making visible the geography of criminality in 19th century Amsterdam, Bologna and Le Havre, by using the mapping software Mapline. The project is built around the concept of 'spaces of awareness': this concept was developed by criminologists to make sense of the spatial patterns seen in contemporary criminality. According to criminologists, offenders are more likely to offend in a place that they know ('are aware of'). This can be where they live, where they work, where they go out or where they do their shopping. To what extent can this concept be applied to 19th-century criminality? Do we see similar patterns, similar spaces of awareness? And was there a gender difference in where male and female offenders committed their crime? This project aims at answering these questions by mapping the address of the suspects and the place where they committed a crime. In addition, these maps will also contain qualitative information on the crime committed, the gender of the suspect, their civil status, etc.
This project will also bring to the fore the importance of socio-economic and cultural contexts in explaining the spatial patterns seen in the archives. 'Spaces of awareness' is a concept which has been difficult to apply to historical studies as the data very rarely contained both the home address of the suspect and the place where the crime occurred, and it still needs to be gendered. In addition to offering a visual of spaces of awareness in these 19th-century cities, this project also makes possible a comparison between men and women’s mobility in the urban environment. For instance, the historiography still tends to see Dutch women as being less mobile than men towards the end of the 19th-century; however, a 'pilot-map' created from the 1905 Amsterdam dataset, shows that male and female suspects were committing thefts at a similar distance from their home. A thorough analysis of their movements in relation to crime, all along the century, will therefore show if their mobility was indeed affected by stricter gender norms ascribed by Victorian values.
Mapping Connections and Interactions in Medieval Literature: Analyzing and Visualizing Social Networks in the Old English Poem Beowulf
Thijs Porck
The early medieval English poem Beowulf presents a complex world inhabited by a multitude of characters who are involved in feuds, alliances and kinship relations. In many ways, the poem focuses on social interactions: kings bind loyal followers to their cause through gift-giving, feuds are solved through political marriages and the killing of kinsmen is repaid through revenge killings. A pilot survey that lies at the basis of the current project has established that Beowulf features more than 76 characters and that there are more than 300 links between these characters, ranging from marriage to physical violence. This project aims to use digital social network analysis tools to study and visualize these social connections and interactions presented in Beowulf, in order to better understand the complex social world presented in this early medieval epic.
This project will experiment with a number of social network analysis tools to visualize and analyze the full range of explicit and implicit links between the characters in Beowulf. In doing so, this project will be able to answer such questions as:
- Who are the most well-connected characters within the poem?
- What roles did female characters play within the social world of Beowulf?
- How do the social networks within Beowulf alter throughout the poem?
- What role does nationality play in the social networks in the poem? (Beowulf features Danes, Frisians, Geats, Swedes, Heathobards and Angles, to name but a few)?
- How does incorporating implicit links between characters, known from other legends, change the structure of the social world presented in Beowulf?
As Baur et al. have noted, “[i]mages of social networks have provided investigators with new insights about network structure and have helped them communicate those insights to others”. Part of this project will, therefore, experiment with social network visualization tools, so as to produce images that may be used for research, teaching and outreach.
Reuniting Manchu Texts on Maps - Designing the Proof of Concept
Fresco Sam-Sin
Since 2014, Leiden University has become the leading online reference hub for Manchu studies. For researchers we have developed:
- Online critical editions and a concordance (Manc.hu);
- An online Manchu lexicon application (Buleku.org);
- An online infrastructure to analyse and compare Manchu maps (QingMaps.org).
This LUCDH grant enables us to take the next step in connecting Manchu data for researchers in Leiden and beyond.
Surrounding the fall of the Daiqing empire in 1912 (but also earlier), European and US institutes and individuals laid their hands on vast collections of Manchu sources. Hence, in many museum and library collections outside China and Taiwan, one can find important Manchu texts. However, collections of texts became separated from each other. One crucial edition of the Manchu rendition of the Mongol Yuan History, for example, is separated, with some volumes in Leiden, many in Berlin, and some draft versions in London. This project intends to reunite editions such as the Mongol Yuan History in a visual, geo-oriented manner, with an understanding of connecting the data in a clear and durable way, adhering to current developments of Persistent Identifiers and Linked Open Data.
The challenge is to present the data in a way that users can easily see where different parts of works are being stored, and how they connect to other editions of the same work. In addition, we want to take on the challenge to connect library collections and museum collections with each other. Until now, all the written Manchu sources in museums (books, rubbings, coins, seals, maps, etc.) have been neglected in the descriptions of Manchu sources. This application intends to meet this challenge.
This project is part of the International Manchu Project (summer 2019-present) an initiative by SOAS (University of London) and Manc.hu (Leiden University/Manchu Foundation). The goal of this project is to digitise and map all Manchu collections outside China and Taiwan. Although large portions have already been digitised, still a lot of work has to be done. Recently, Leiden University Libraries has started the digitisation of its own Manchu collection. Combining this LUCDH grant with funding from SOAS, we aim to present a first iteration of the Manchu collections map, that may be used as a framework for other collections in Leiden as well.

L-SEVIR : Literary Segments to Visualize Italian Realism
Carmen Van den Bergh
This project aims to be a first step towards redefining the concept of "realism" in the panorama of Italian literature of the first half of the Twentieth Century (1900-1950) based on the study of a very peculiar genre, the "Elzeviro". This is a hybrid literary segment that can be compared with journalistic essays on the one hand, and with literary short stories on the other. These segments were mainly published in newspapers as editorials of the cultural page and have, therefore, have been under-studied by literary scholars. For these reasons one can speak of a neglected genre, or also “cinderella-genre”. (Ansary & Esmat Babaii 2005).
More specifically, work will be carried out on one particular case study : a corpus of 154 elzeviri by Italian writer Grazia Deledda (first female Nobel Prize winner for Literature in Italy) published between 1910 and 1936. The aim is to map the number of literary segments that Deledda wrote for the Corriere della Sera and to analyze them for a number of prototypical features of both verismo and modernismo, starting from the use of time and space: from a naturalistic setting that underlines the couleur locale in a "positivistic" way, to a more modern interpretation of the city where the protagonist finds impulses for introspection.
This project aims to:
- Get a better understanding of this hard-to-grasp literary genre (elzeviro) and aesthetic category (realism).
- Valorize and unveil the unexplored corpus of one of Italy's greatest writers and do justice to its complexity. The "label" of veristic writer which seems too narrow, will be questioned and challenged.

Touchy-Feely: Text-mining as an Expansion of Qualitative Emotion Analysis
Timothy Vergeer
In the seventeenth century, the most popular plays in the Netherlands were not those written by Joost van den Vondel, but the translations of plays written by the Spanish playwrights Lope de Vega and Calderón. The Spanish plays often relate the stories of star-crossed lovers who have to fight their parents, other suitors, or society for them to be together. By contrast, Dutch plays have often been regarded to propagate moderation, rationalism, and conformism. People in the early modern period generally believed that Dutch people were cold-hearted, whereas Spanish people were hot-tempered. The same stereotypical language was used for their respective literatures. Nevertheless, Dutch people very much enjoyed Spanish plays. Why? Because Spanish plays were maybe emotionally more exciting?
In this project, I will endeavour to corroborate this question by using text-mining tools. And what else can we find, if we start looking for emotions in these plays with the help of text-mining? I will adopt the so-called Historic Embodied Emotions Model (HEEM) as developed by the Amsterdam Centre for Cross-Disciplinary Emotion and Sensory Studies at VU University. The VU research centre has linked emotions to embodied speech (e.g. 'mijn bloed kookt van woede', meaning you are angry as a figure of speech in Dutch). Subsequently, those utterances were categorized according to four emotional concepts: emotion, body part, bodily response, and emotional action. These concepts can enlighten the focus of emotions in Spanish and Dutch drama: Which emotions are predominant in both types of drama? And which body parts play a role, when those emotions are uttered? As women in Spanish drama seem to have a more proactive role than in Dutch drama, the question will also be which character utters which emotions.
I will compare plays of Spanish origin and canonical plays by several Dutch playwrights, including Vondel, Hooft, and Bredero. As such, it will be explored whether HEEM can be used to differentiate between different early modern theatrical genres on the basis of embodied emotions. I will look at Senecan-Scaligerian, Spanish, Vondel’s biblical, and the French-Classicist plays by Nil Volentibus Arduum. As such, HEEM will be used to see how playwrights reworked the Spanish plays in terms of their emotions to fit the Dutch context and experiences of the spectators.
An Online Cross-linguistic Database of Sound Changes
Xander Vertegaal
One of the most important types of language change is sound change, a gradual, regular change of pronunciation that is usually unnoticed by the speakers that produce it. Historical phonologists study this type of change intensively, and try to explain how and why it happens in the way it does. It has long been known that some sound changes (e.g. [s] > [h] in between vowels; [nt] > [nd]) are very common in the world's languages, while their inverse variants ([h] > [s], [nd] > [nt]) does not seem to be attested anywhere at all. Currently, our knowledge about these directional patterns of sound change are scattered across the scientific literature. This forces scholars who want to judge the plausibility of a certain change to rely on an 'instinct', based on their experience with sound changes they happen to have seen before.
This Digital Humanities Small Grant will be used to develop a research proposal to set up an online cross-linguistic searchable database of sound changes: CoPhon (Codex Phonica). A community-built collection of reported sound changes, this database allows us to replace historical linguists' gut feelings about plausible or implausible sound changes with quantifiable data and will allow them to find parallels for particular sound changes they need in their research. It will also help us understand how often and why particularly sound laws occur, as well as when/why they often do not take place.
Mapping the Mandate: Frank Scholten in the "Holy Lands"
Sary Zananiri
Mapping the Mandate: Frank Scholten in the ‘Holy Lands’ is a pilot project that, in conjunction with the digitisation of the NINO’s Frank Scholten collection, financed by NINO and Leiden University Libraries (2020-2021), will build a user-friendly interface that geo-locates the more than 20,000 photographs in the collection.
Frank Scholten was a Dutch photographer who travelled through the Middle East from 1921-1923. In the two years he was in the Levant, he photographed the shift from Ottoman rule to Mandate administration, primarily in British Mandate Palestine, but also Transjordan and Mandate Lebanon and Syria.
The Scholten collection is undisclosed so far. Our project will make the collection available in tandem with a digitisation project planned at UBL and co-funded by the NINO. Mapping the Mandate will make a targeted contribution to this initiative by developing a tool to study the complex communal geographies Scholten photographed and easily communicate this to a wider audience. This information will give us specific data on the spread and transregional movement of different communities as well as contextualising the differences between urban and rural life, overlaying this with cross-confessional interactions. In doing so, we can begin to understand the effects of British rule and the ways in which this political transition interacted with the Ottoman modernist project.
Small Grants 2019 Research Projects
Linguistic Typological Databases
Lisa Bylinina
TBA
Digging in Documents: Using Text Mining to Unlock the Hidden Knowledge in Dutch Archaeological Reports
Alex Brandsen
In this project, we are developing an advanced search engine for Dutch archaeological excavation reports, called AGNES. Archives in the Netherlands currently contain over 70,000 excavation reports and this number is growing by 4000 a year. This so-called ‘grey literature’ contains vast amounts of knowledge stemming from millions of euros in funding, but are barely being utilised at the moment, mainly because researchers have trouble finding the information they need. The reason for the limited access is that the documents can only be searched by their metadata; the full text is not indexed yet for keyword search. Questions like “find all cremation remains from the early Middle Ages around Amsterdam” are currently impossible to solve without reading all the documents.
A unique feature of our method is that we develop a method for semantic search in the archaeological domain. The indexing method will use machine learning to automatically recognise and distinguish between archaeological concepts in the text, such as time periods, artefacts, materials, contexts and (animal) species. This will make searching a lot easier and quicker.
To be able to do this, we need text that is labelled by humans, called training data. Labeling data is a very time intensive process, and we are very happy that the LUCDH is providing us with funds to be able to create this training data.
22 July 2020 update: The article, "Creating a Dataset for Named Entity Recognition in the Archaeology Domain", describing this work has been published at: lrec-conf.org/proceedings/lrec2020/pdf/2020.lrec-1.562.pdf
Unopened Pleadings: The Records of London’s Court of Wards and Liveries
Lotte Fikkers
Manuscript collection WARD 16, held at The National Archives (Kew, UK), comprises 436 unopened letters and packages from the sixteenth and seventeenth centuries. Based on the addresses on these letter bundles, in as far as these are still legible, it seems each letter contains legal pleadings (the textual by-product of legal proceedings, such as bills of complaint, answers, interrogatories, and depositions) sent to the Court of Wards and Liveries and the Court of Requests in London. It remains a mystery why these documents have never been opened. Opening up these manuscripts might solve this mystery, but has the disadvantage of being something that is irreversible: once opened, it is impossible to return the letter to its unopened state unharmed. Since the letter as artifact is worthy of attention and analysis in and of itself, opening these closed manuscripts is to be avoided. The Apocalypto team at the Dentistry Department at Queen Mary University of London has developed a technique that makes it possible to reveal the contents of a closed manuscript, without damaging or opening it. As such, the letter can be studied as artifact, while at the same time making it possible to reveal its hidden secrets.
The LUCDH’s small grant makes it possible to strike up a conversation between The National Archives, the Apocalypto team, and Leiden University, with the aim of x-raying a sample of manuscripts, and as such, making the unreadable readable.
Go with the Flow? Fluvial Chronotopes and Cultural Identity in Early Modern Italian Poems
Emma Grootveld
This research projects aims to investigate ways of representing rivers in ‘literary worlds’ of the Italian Renaissance. The aim of the project is to develop one or more samples for the digital visualization of these worlds, in which extraliterary, ‘real world’ geography is combined with fictional, imaginative geography. The project serves as a technical preparation for the Veni-proposal (to be submitted in August 2019) of a research project that aims to investigate the pivotal role of rivers in constructing cultural and literary identity in early modern Italian epic poetry.
Extracting Social Networks from Thematic Research Collections: The Genealogical Networks of the Group of Chungin in Chosŏn Korea
Jing Hu
This project aims at mapping the genealogical networks of the group of chungin (middle people) of the Chosŏn dynasty, in an attempt to examine the origin and the development progress of the chungin group in Chosŏn Korea.
In the social hierarchy of Chosŏn Korea, the chungin was a group ranked between the yangban (aristocracy) and the commoners. The social mobility of the chungin is one of the central issues in the social history of Korea. Previous scholarship reveals that the group of chungin intensively developed around the middle 17th century. Although there has been no conclusive research on the origin of the group, some scholars claim that the chungin group was branched from downgrade yangban aristocrats. However, due to the absence of a tool enabling a macroscopic investigation, scholars have only been able to test the hypothesis by case studies of partial families.
The first goal of the project is to test the hypothesis that the chungin was a group branched from the downgrade aristocrats. By extracting genealogical information from big datasets like the bangmok (Rosters of Imperial Examinations), it allows us to map genealogical networks of different social groups in Chosŏn. In order to investigate the relation between the aristocracy and the middle people, the network interconnects the lineage and marriage data of both the yangban and the chungin groups.
Additionally, the project also contributes to filling up the gap of the digital infrastructure for chungin studies, a field which has received limited attention in Korean Studies. The final outcome of the project is designed as an intractable platform of visualized genealogical networks. Users are allowed to manipulate the networks by querying with time reference, regions, families or types of relationships (lineage or marriage). In this way, the project takes the initiative to benefit studies on minority social groups in the Chosŏn dynasty by opening up a new digital avenue.
Developing a Proof of Concept on the Digital Documentation and Material Analysis of the Painted Decoration of Theban Tomb 45, Luxor, Egypt
Carina van den Hoven
In November 2017, the Egyptian Ministry of Antiquities granted Carina van den Hoven (NINO/LIAS) the concession for Theban Tomb 45 in Egypt. This beautifully decorated tomb dates to ca. 1400 BCE and is situated in the Theban necropolis, a UNESCO World Heritage Site close to modern Luxor. Theban Tomb 45 is a fascinating case of tomb reuse. The tomb was built and partly decorated with painted scenes and texts around 1400 BCE for a man named Djehuty and his family. Several hundred years later, the tomb was reused by a man called Djehutyemheb and his family. Even though the practice of tomb reuse calls to mind images of usurpation, tomb robbery and destruction, Theban Tomb 45 was reused in a non-destructive manner, with consideration for the memory of the original tomb owner. Instead of vandalising an earlier tomb and whitewashing its walls in order to replace the original decoration with his own, the second tomb owner left most of the existing decoration in its original state. He added his own decoration only to wall sections that had been left undecorated by the first tomb owner. He also retouched a number of the original paintings. For example, he altered the garments, wigs and furniture depicted on the tomb walls, in order to update them to contemporary style.
(For photographs, see the project website: www.StichtingAEL.nl)
Dr. van den Hoven has obtained funding from the Gerda Henkel Stiftung for the conservation of the wall paintings as well as for heritage preservation and site management activities in Theban Tomb 45. With the grant from the Leiden University Centre for Digital Humanities, she undertakes a pilot project in order to develop a proof of concept on the digital documentation and material analysis of the painted decoration of this tomb, with a special focus on the repaintings that were carried out by the second tomb owner.
An important aim of the fieldwork project in Theban Tomb 45 is to contribute significantly to the development of new standards for the documentation, analysis, publication and accessibility of ancient material culture. With the help of non-invasive digital imaging technologies we aim to create a scale 1:1 digital record of the tomb, which documents not only its architecture and decoration, but which also functions as a digital tool to interactively investigate the monument even after leaving the field.
Another important aim of the project is to test the usefulness of photo processing software applications and digital imaging technologies in the material analysis of ancient wall paintings. Part of the painted decoration of Theban Tomb 45 has faded over time and is now barely visible with the naked eye. In rock art studies, the software application ImageJ (and in particular its plugin DStretch) has been used successfully to enhance images of pictographs that are invisible to the naked eye. We aim to test the usefulness of photo processing software applications and digital imaging technologies in enhancing the legibility of faded wall paintings, as well as in identifying and analysing wall paintings that have been retouched or repainted in antiquity.
The investigation of the materiality of the (re)painted tomb decoration of Theban Tomb 45 allows us to open up new research opportunities on the question how the ancient Egyptians engaged with and perceived their own cultural heritage.
Links to websites:
www.nino-leiden.nl/staffmember/dr-c-van-den-hoven
Digital Curation of The Leiden Williram
Peter Kerkhof
The Leiden Williram, an eleventh-century text that is decades older than the hebban olla vogala poem and the sole substantial Old Dutch text that has come down to us in an original manuscript, has thus far only been accessible to a handful of scholars. Although the text can be consulted in the 1971 edition of Sanders or via the pdf-version of the digitized manuscript at the Leiden University library website (manuscript BPL 130), the linguistic character of the Leiden Williram and its philological context requires specialized philological expertise in order to gauge and appreciate the Dutch nature of it. This is because the Leiden Williram is a Dutch copy of a German commentary to the Song of Songs, authored by Williram von Ebersberg. The Dutch copyist, probably working in the scriptorium of Egmond, respected most of the German grapho-phonemic conventions, but adapted the language at the morphological and lex ical level to its own Dutch dialect, thereby giving the Leiden Williram a hybrid linguistic identity (cf. Sanders 1974). Because of its linguistic opaqueness, it may come as no surprise that the significance of the Leiden Williram for Dutch cultural heritage is largely unknown to a wider Dutch public.
The aim is to develop a proof of concept for a digital edition of the Leiden Williram in which the Old Dutch lexis and Old Dutch morphology of the text can be highlighted at the click of a button, thereby disclosing the value of the text to a 21st century audience and making the Old Dutch nature of the text available to non-linguistic scholars and an interested lay public alike. This innovative digital curation of the text will be executed by providing a TEI-compliant (Text Encoding Initiative) XML edition, based on the 1971 edition and the digitized manuscript. The text edition can then be published online on a dedicated website, hosted on Leiden University servers under a Creative Commons license.
Semantic Treasure Troves: Historical Thesauri and the Semantic Web
Sander Stolk
Project EASE: Working with A Thesaurus of Old English and the Digital Platform Evoke
Which lexical items were available to the early medieval author Cynewulf or to the Beowulf poet? How many words did these authors have available to them to express war, contrasted with the number available to express peace? Which words seem to have been restricted to poetry, and do such restrictions appear to have had an impact on the word choices these authors made when they wrote their texts? Which words did the Beowulf poet prefer over others that expressed the same notion? Just such questions are intended to be answered by means of the proof of concept worked on in the EASE project, which utilizes the dataset of A Thesaurus of Old English.
A Thesaurus of Old English is a lexicographic resource that organizes Old English words and word senses according to their meaning. This topical fashion to organize lexical items allows one to look up available alternative phrasings, but thesauri such as this one offer a number of uses beyond that: they are veritable treasure troves for cultural, linguistic, anthropological, and literary-critical research (as indicated by the illustrative questions in the previous paragraph). However, the current forms in which the majority of these thesauri are available make it difficult for scholars to use them to the fullest. In making A Thesaurus of Old English and other thesauri available in a more suitable form for use and reuse – bringing them to the semantic web as Linked Data – and developing a platform to work with this material, this project set out to facilitate a wide variety of research that focusses on the vocabulary and culture of current and past times.
In the EASE project, we aim to elicit what researchers (from various disciplines) want to investigate about early medieval English language and culture through A Thesaurus of Old English. The research questions and case studies that the participating researchers formulate have been used to inform development of the Evoke platform to result in a proof of concept fit for purpose, available at www.evoke.ullet.net/. This digital platform is meant to make it easier for users to access Linked Data thesauri, query them, filter them, and expand them – a platform for which one need not be a computer scientist in order to utilize. Thus, the materials and tooling created in the EASE project will allow both established researchers and students to ask powerful and evocative questions, making Digital Humanities more accessible to a larger group of people. The results of the project will be presented at a workshop that is part of the 21st International Conference of English Historical Linguistics (ICEHL-21) in Leiden, 8 June 2020.

Small Grants 2018 Research Projects
Numismatics in Leiden: More than Two Sides to the Same Coin
Liesbeth Claes
The use of numismatic sources is incorporated in Claes’s research project “Dialogues of Power”. This project aims to analyse the legitimising dialogue between Roman emperors and their Germanic legions during the so-called “crisis of the third century”. By doing so, this project will shed new light on how the loyalty of soldiers towards their emperors was established and which communication strategies emperors used to (re-)gain the political and military stability that ultimately helped to reunify the Roman Empire after the crisis.
Because imperial coinage is a direct vehicle for imperial communication, various messages, visual and verbal, could be disseminated by them. In the third century, silver coins still formed the major part of soldiers’ payments. This means that the imperial centre had an excellent tool to send messages addressing the military. For instance, messages of victories or trust in the army on these silver coins could flatter soldiers in order to win their loyalty.
The analysis of coin messages will be based on coin hoards, deposited between AD 180 and 285 in and near the military zone of the Lower Rhine limes, especially at the military camps in Germania Inferior. Although hoards often represent a random sample taken from circulation, hoard-based samples represent an untouched record from antiquity, providing information about the period in which the coins were used and deposited. Moreover, these coins from hoards give us additional information as opposed to single coin finds. The date of the youngest coins in a hoard give us a terminus post quem for the date at which coins stopped to be added to the hoard and the composition of a hoard can give us an idea about the date of the deposition of the coins, which may be different from the closing date. Most coins composing a hoard were probably withdrawn from circulation within a short space of time before the date at which the saving process ended. All in all, it can give us an idea when certain coin messages were disseminated. Additionally, hoards are found abundantly at the Empire’s northern border, and more importantly, the coins’ withdrawal from circulation was not related to the messages on them.
Developing Proof of Concept: The effects of Dutch colonial redistributive policies on current ethnic-based inequalities in Indonesia
Rizal Shidiq
I plan to develop a proof of concept for the long-run effect of government policy on ethnic-based inequalities. My specific research question is: Does Dutch colonial redistributive policy affect ethnic-based economic inequalities in contemporary Indonesia? My proposed research shares micro-level approach with standard analysis on inequalities but differs from the existing literature in the following way. First, it takes a long-run perspective back to the Dutch colonial administration days and, if feasible, even longer in the past. Second, it explicitly estimates the causal effects of redistributive policy on between-ethnics inequalities. Third, the focus is not only on the one-time effect but also on its persistence and durability. Fourth, it will generate and use a new digitized modern-standard dataset from old administrative records, in addition to present-day socio-economic and geographic information system (GIS) data, for the analysis.
In this proposed proof of concept development stage, I ask the following simple questions: Are household-level and/or village-level colonial administrative data in the last 19th and early 20th centuries available and accessible? If so, is it feasible to identify and reconstruct the variables of interest using text-mining and GIS procedures? Is it also possible to identify relevant colonial redistributive policies and their actual implementation at household or village level? In other words, this project is akin to a feasibility study to assess whether the available data permits for digital-humanities pre-processing and further statistical causal inference estimation on certain level of units of analysis (either household- or village- or sub district-level). If there is a positive result, I plan to scale up the project for a large-scale text-mining and GIS exercises to produce high-quality datasets that can be used for my and other interested researchers’ studies on the persistent effects of colonial policies on ethnic-inequalities and other socio-economic indicators.
Tanti’s Letters: An exploration into the words and life of a non-Muslim woman living in Istanbul (1954-1974)
Nicole van Os and Deniz Tat
This project aims at the digitalization and preparation for further analysis of approximately 550 letters written between 1954-1974 by a non-Muslim, non-Turkish single woman living in Istanbul to her niece in the Netherlands. These letters, which are written in a mixture of languages including French, English, Turkish and some Greek and Italian, are of interest to scholars of two separate disciplines: social historians and linguists. They are of interest to social historians, because they provide a unique insight into the multi-lingual environment of the Istanbulites belonging to minority groups during a period of political turmoil which made the lives of members of these groups much harder. They also provide us with detailed information about the (social) life of a single woman, working as a teacher, in a period that the position of women changed.
The letters are also of interest to linguists since the frequent code-switches between typologically distinct languages have structural, psycholinguistic and sociolinguistic implications. Frequent classical, or intra-sentential switches in these letters provide us with an opportunity to understand how a multilingual speaker exploits her ability to alternate, let’s say, between Turkish, a scrambling SOV language with no grammatical gender, and English, an SVO language with relatively strict word order, or French, a language with grammatical gender. In this respect, it is a unique opportunity to shed light on how word-order, information structure, structural and inherent case, phi features (e.g. number, person and gender) are determined in code-switching.
After the initial digitalization of the handwritten letters, we will investigate the possibility of automatic detection of socio-historically relevant items in the corpus on the one hand and the automatic detection of code-switching, on the other hand. Moreover, we plan to develop a way to detect patterns by cross-referencing these two sets of data to determine how code-switching relates to different domains of life referred to in these letters.
Slave Registers Digital Archive – Ceylon (Sri Lanka) - 1818-1832
Nira Wickramasinghe
The National Archives in London, Kew have made available (online) the slave registers that the British colonial government mandated in Sri Lanka/Ceylon between 1818-1832. The same database exists for 16 other slave colonies of the British including Barbados, Jamaica, and Trinidad. In the case of Sri Lanka this data has never been collected or analyzed in a systematic way owing to the large number of entries. The proposed research entails in the first instant transcribing the 828 images in the slave registers on Jaffna (www.search.ancestry.com/search/db.aspx?dbid=1129) onto excel sheets and creating an easily consultable database. With this research I hope to create a data base of over 10 000 slaves that will contain such information as the name/gender of owner, the place of residence, name of slave (slaves in Jaffna unlike slaves brought from outside the island kept their names), gender of slave, age of slave, children of slave, date of manumission, other details (death for example).
This data once collected will be a unique source to reconstruct society in Jaffna, add complexity to our understanding of the structure of the caste system, produce insights into land ownership and labour patterns according to produce (tobacco or palmyrah etc..) It will also allow us on occasions to trace the lives of particular individuals, slaves or proprietors in the registers that I have encountered in my other archival source material, court cases or petitions. This project will feed into my on-going book project entitled ‘Slave in a Palanquin. Slavery and Resistance in an Indian Ocean Island’.
Infrastructure of Empire and War
Limin Teh
This project investigates the role of industrial infrastructure in Northeast China in shaping the events and outcome of the Chinese Civil War (1946-1950). It asks:
- How did the Chinese Nationalist Army lose the Chinese Civil War (1946-1950)?
- Did the effect of variation of industrial infrastructure on military campaign make the Chinese Nationalist Army lose the Chinese Civil War?
In Northeast China, the industrial infrastructure— transportation network, electric grid, mining and manufacturing facilities, and urban built environment—was developed under Japanese control (1931-1945). After the fall of the Japanese empire in August 1945, the regional industrial infrastructure attracted the attention of postwar powers. The Soviet Union and the United States competed with each other to take over the region from Japan. The Soviet Red Army, which won the competition, removed large portions of the industrial infrastructure as they retreated in March 1946. The violent rivalry between the Chinese Communists and the Chinese Nationalists erupted here as they sought to seize control over the region. In spite of its overwhelming advantages in troop size and firepower, the Chinese Nationalist army unexpectedly lost to the Chinese Communist in 1948.
Historians generally agree that a correlation exists between the region’s industrial infrastructure and the Chinese Civil War, but rarely agree on the degree or nature of this correlation. This project seeks to illuminate this correlation between these two variables: the damaged industrial infrastructure and the logistical needs of military campaigns. It uses GIS to map out the spatial distribution of industrial infrastructure and military campaigns, and to analyze the spatial correlation between these two variables. In doing so, it aims to obtain a nuanced picture of the material conditions shaping the unfolding of this military event.
Uniformity vs. variability in Spanish/English code‑switching
Carmen Parafita Couto
It is well known that bi-/multilinguals in some bi-/multilingual communities combine languages in the same sentence when they communicate with one another, known as code-switching. Most researchers agree that code-switching is not a random mix of languages, but that it is rule-governed. Recent work by members of our research team using different language pairs has established that, in general, multilingual speakers choose the morphosyntactic structure (word order and grammatical morphemes, making up the ‘matrix language’) of just one of their languages and insert words or phrases from their other language(s) into the selected frame (Parafita Couto et al. 2014; Parafita Couto & Gullberg, 2017). Although this pattern has been established in different bilingual communities, to our knowledge no previous study has examined in more detail the factors which determine the choice of the matrix language.
In this pilot study, we investigate the extent to which this choice is based on speaker characteristics as compared with community norms, while holding the language pair constant. As the first stage of a larger project involving cross-community study of comparable communities in other geographical locations, we focus on two Spanish/English bilingual communities, Miami (USA) and Gibraltar (Europe). The contexts of Miami and Gibraltar provide a clear contrast both in terms of geographical location and history. Data from both locations has already been collected in the form of natural speech conversation, and the Miami data has already been transcribed and coded (www.bangortalk.org.uk/). We will transcribe and code the Gibraltar data in a similar way to the Miami data in order to facilitate comparison between the two datasets. This will enable us to identify what the code-switching patterns in the two communities have in common and how they are different.
By focussing on only Spanish/English in different communities, we will be able to show to what extent the occurrence of a particular switching strategy may be traced to the influence of syntax/grammar and extralinguistic factors (e.g. social network, attitudes, etc.).