Research project
EXALT: Excavating Archaeological Literature
We will use Artificial Intelligence to make an intelligent, multilingual search engine for archaeological texts, which will enable new discoveries about the human past.
- Duration
- 2021 - 2025
- Contact
- Karsten Lambers
- Funding
-
 NWO - Future directions in Dutch archaeological research (NWA)
NWO - Future directions in Dutch archaeological research (NWA)
- Partners
Project description
The amount of text archaeologists create has been growing at an ever increasing rate, making it difficult and time-consuming to find relevant information in this big data. Currently, we can only search through the metadata of archaeological documents. This metadata is often incomplete, making searching inaccurate, and manual reading of full documents is required after the search to find relevant information. Text mining and semantic search techniques have become available over the last decades, which can provide a computational way to access information from this wealth of valuable but underused literature.

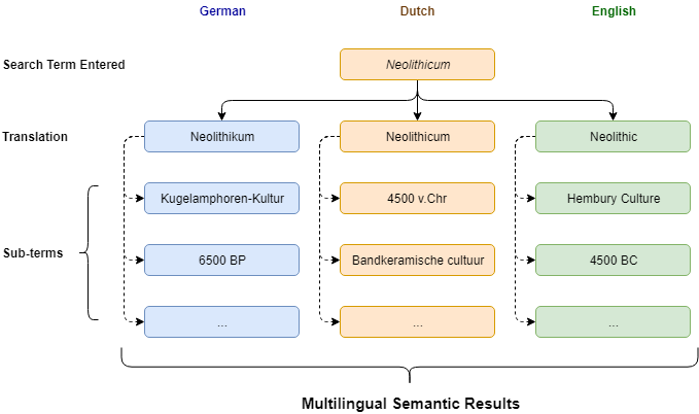
Searching with Artificial Intelligence in multiple languages
In the EXALT project, we are building a search engine for archaeological documents, which uses Artificial Intelligence to make searching better and faster. In a previous project, we built a prototype search system for Dutch archaeological reports from the DANS repository, but in EXALT, we will be adding documents in multiple languages (English, Dutch, German) and from different sources, for example the Dutch National Library, the Archaeology Data Service in the UK and Agentschap Onroerend Erfgoed in Belgium. The goal is to include as many documents as possible from the Netherlands and surrounding areas, to give archaeologists the best possible starting point for literature research.
Synthesising research leading to new insights
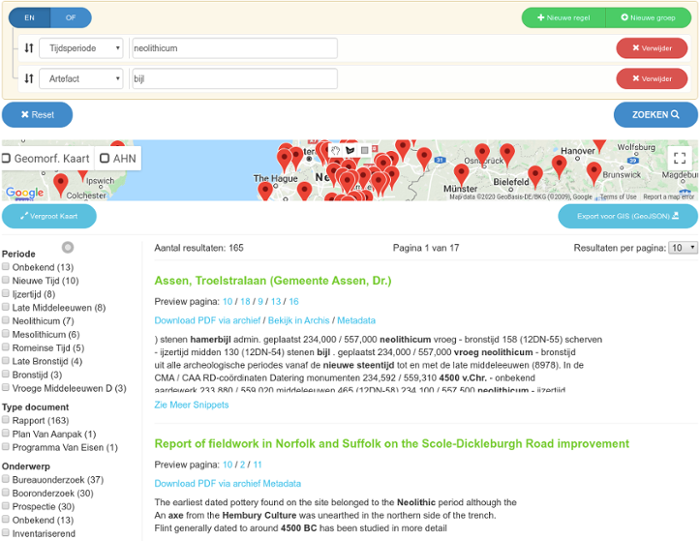
Being able to find and access literature more easily will make it possible to do research on broad topics as well as specific, uncommon topics. Having all that information at our fingertips can challenge existing ideas and provide inspiration for new theories. In a case study with the prototype search system, we investigated Early Medieval cremation burials in the Netherlands, and found 23 new sites: an increase of 30% over the existing knowledge of experts. This newly rediscovered information is now challenging the traditional view that inhumation burials were more common in this period.
From the Stone Age to supercomputers
The archaeological documents describe ancient artefacts and sites, but to process them with state-of-the-art analysis techniques, we need modern computers with powerful GPUs, and technical know-how on how to use these. Leiden University provides the ALICE high performance computing facility, with enormous amounts of computing power. We also leverage insights from previous projects at the Faculty of Archaeology and collaborate with LIACS in an interdisciplinary setting, combining archaeological knowledge and technical expertise.
Methods: Text Mining and Machine Learning
To facilitate semantic search, we will use Named Entity Recognition (NER), a Text Mining technique that can automatically recognise and classify concepts from text. In the case of archaeology, the concepts we are often looking for are artefacts, time periods, locations, etc. We propose to use the recently popularised Transformer based language models, which are currently achieving state-of-the-art performance on similar tasks. Once the entities (or concepts) have been detected, we can use ontologies to map relations between entities, allowing for semantic, multilingual search.