

Tim van Erven maakt computers nog slimmer
Op de middelbare school las Tim van Erven over een kunstmatig intelligent algoritme dat doolhoven kon oplossen. Vanaf dat moment was hij verkocht: ‘Het heeft iets magisch dat je met een lijst vaste regels algoritmes kunt maken die de meest verschillende dingen kunnen leren.’ Dit jaar haalde hij een Vidi-beurs binnen, waarmee hij algoritmes nog sneller wil laten leren.

Machine Learning
‘Data science kent steeds meer gave toepassingen, kijk maar eens naar de projecten op onze eigen universiteit,’ zegt Van Erven. In zijn vakgebied Machine Learning worden algoritmes en technieken ontwikkeld waarmee computers kunnen leren. ‘Met deze zelflerende computers speuren we naar nieuwe verbanden en informatie in grote hoeveelheden data.’ Maar waar halen mensen hun algoritmes vandaan, zijn de berekeningen betrouwbaar en kan het niet efficiënter? Dat is het domein van Van Erven. ‘Ik werk aan nieuwe deelalgoritmes en de wiskundige theorie daarachter die beschrijft hoe goed ze werken onder verschillende omstandigheden.’
Algoritme past zich aan
‘Ik ontwikkel zogenaamde adaptieve algoritmes’, vervolgt Van Erven. ‘Dat wil zeggen: algoritmes die zelfstandig hun leerstrategie aanpassen aan de moeilijkheid van de data.’ De moeilijkheid van data bepaalt namelijk hoe zorgvuldig je ermee om moet gaan. Bij lastige data met veel ruis bestaat het gevaar dat een computer patronen in de ruis ziet die er helemaal niet zijn. ‘Net zoals wij figuurtjes zien in de wolken, of een sneeuwbeeld op tv’, legt Van Erven uit. Voor deze data moet je dus terughoudend zijn met wat je leert. Snelle conclusies zijn in dit geval vaak onzinnig en onbetrouwbaar. Bij makkelijke data met duidelijke verbanden speelt dit probleem niet, en kun je algoritmes gebruiken die veel sneller patronen vinden. ‘Het is dus een constante afweging’, aldus Van Erven. ‘En precies daarom werk ik nu aan adaptieve algoritmes die aan de hand van de data zelf bepalen of deze moeilijk of makkelijk is en welke leerstrategie ze moeten toepassen.’
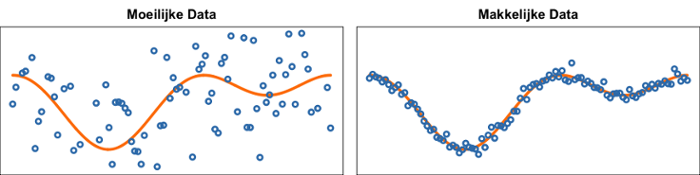
Grote datasets
Van Erven kijkt hierbij naar algoritmes die de data sequentieel verwerken. Hij legt uit: ‘Als je werkt met hele grote datasets, kan de computer die niet in één keer verwerken. Denk bijvoorbeeld aan een database met 200.000 websites, waarvan de computer moet leren herkennen welke echt en welke frauduleus zijn. Je wilt dan een machine learning algoritme maken dat op basis van misschien wel 100.000 kenmerken kijkt welke kenmerken op welk soort sites voorkomen.’ Om zo’n enorme dataset te kunnen verwerken, is een sequentieel algoritme nodig. Dat zorgt dat de computer één website per keer bekijkt, daarvan leert en dan doorgaat naar de volgende. ‘Juist grote datasets kunnen ons veel informatie verschaffen, maar dan moet je wel de geschikte algoritmes hebben en deze ook op kunnen schalen naar zulke hoeveelheid data,’ aldus Van Erven.
Fundament
Het onderzoek richt zich echter niet op één concrete toepassing, maar juist op de theorie erachter. ‘Anders dan toegepaste datawetenschappers richt ik me niet op één dataset of doel. Als je bijvoorbeeld frauduleuze websites wilt opsporen, geef je minder om de methode en wil je gewoon een nuttige uitkomst. Veel huidige methodes zijn als een black box, en veel aspecten hiervan begrijpen we nog niet goed.’ Maar als je vooruit wilt, is wiskundig begrip van nieuwe methodes belangrijk, vindt Van Erven: ‘We bouwen steeds ingewikkeldere machine-learningsystemen. Als je dat moet doen met componenten waarvan je niet precies weet hoe ze (goed) werken, dan houdt het op een gegeven moment op. Hij ziet het ook wel als het fundament van een toren: ‘Als je de toren hoger wilt maken, moeten de fundamenten steviger en betrouwbaarder zijn. Dat is waar ik mee bezig ben.’
Met de Vidi van 800.000 euro kan Van Erven twee promovendi en 1 postdoc aannemen. Het project duurt 5 jaar.
Tekst: Hilde Pracht - Altorf