

Tim van Erven makes computers even smarter
In high school, Tim van Erven read about an artificially intelligent algorithm that could solve mazes. From that moment on, he was sold: ‘There’s something magical about algorithms. With a list of fixed rules you can make them learn the most diverse things.’ This year, he won a Vidi grant, which he will use to make algorithms learn even faster.

Machine Learning
'Data science has more and more cool applications, just take a look at the projects at our own university’, says Van Erven. In his field of Machine Learning, algorithms and techniques are being developed that enable computers to learn. ‘With these self-learning computers, we search for new relations and information in large quantities of data.’ But, where do people get their algorithms from, are the calculations reliable and couldn’t they be more efficient? That is the domain of Van Erven. ‘I’m working on new sub algorithms and the mathematical theory behind them, which describes how well they work under different conditions.’
Algorithm that adapts
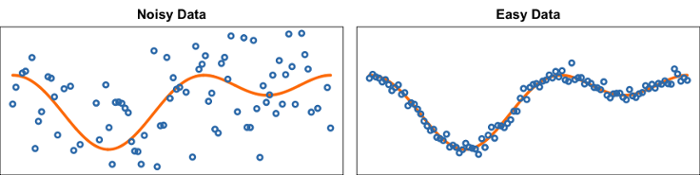
‘I’m developing so-called adaptive algorithms’, continues Van Erven. ‘That is to say: algorithms that self-adapt their learning strategy to the difficulty of the data.’ The difficulty of the data after all determines how carefully you should handle it. With difficult, noise-filled data, there is a risk that the computer will see patterns in the noise that are actually not present at all. ‘Just as you and I see figures in the clouds or in the ‘snow’ on an old tv screen,’ explains Van Erven. So for these data, you have to be more cautious about what you learn. Quick conclusions are in this case often pointless and unreliable. With easy data with clearer correlations, this problem does not arise, and you can use algorithms that find patterns much faster. ‘So, it is a constant weighing of factors,’ says Van Erven. ‘And that is exactly why I am working on adaptive algorithms that determine by themselves on the basis of the data whether it’s difficult or easy and which learning strategy they should apply.’
Large datasets
Van Erven is looking at algorithms that process the data sequentially. He explains: ‘If you work with very large datasets, the computer cannot process everything at once. Think, for example, of a database of 200,000 websites, from which the computer has to learn to recognise which one are real and which are fraudulent. You want to create a machine learning algorithm that determines which characteristics occur on which types of sites. For 200,000 websites, this could be based on up to 100,000 characteristics.’ To process such an enormous dataset, a sequential algorithm is needed. This enables the computer to view one website at a time, learn from it and then move on to the next. 'Large datasets in particular can provide us with a great deal of information, but you must have the appropriate algorithms and be able to scale them up to such a large amount of data,' says Van Erven.
Fundament
However, the research does not focus on one specific application, but rather on the theory behind it. 'Unlike applied data scientists, I do not focus on a single dataset or goal. For example, if you want to detect fraudulent websites, you care less about the method and you just want a useful outcome. Many current methods are like a black box, and many aspects of this are not yet well understood.' But if you want to move forward, mathematical understanding of new methods is important, says Van Erven: 'We are building increasingly complex machine learning systems. If you have to do that with components of which you don't know exactly how they work (well), then at some point it will come to a halt.' He compares it to the foundation of a tower: 'If you want to make the tower higher, the foundations must be stronger and more reliable. That's what I'm doing.'
With a Vidi of 800,000 euros, Van Erven can take on two PhD students and one postdoc. The project takes 5 years.
Text: Hilde Pracht - Altorf