

Ei van Columbus: eenvoudige statistiek optimaliseert fotokwaliteit
Bij 'gewone' digitale foto’s is het niet erg dat er fouten in zitten door kapotte pixels, bij röntgen- en wetenschappelijke foto's wel. De Leidse hoogleraar Marin van Heel presenteert op de site van Nature een nieuwe ‘kinderlijk eenvoudige’ methode om specialistische foto's te optimaliseren.
Sensoren van 16 megapixels
Ondanks dat filmmateriaal een goed medium was, is ook de wetenschap vrijwel geheel overgegaan op digitaal, en niet alleen vanwege het gemak: de moderne sensoren zijn gevoelig en goed voor bijvoorbeeld 4096 bij 4096 pixels ofwel 16 megapixels. Dan heb je geweldig scherpe beelden. Maar anders dan bij film worden de pixels steeds weer opnieuw gebruikt voor een volgende opname. Hun functie is dat ze licht opvangen en daarmee zorgen voor de kleur in een opname.

Kapotte pixels
‘Op de sensor zijn echter altijd een paar pixels stuk’, zegt Van Heel, ‘soms zelfs een hele rij of een blokje. Zoals het nu gaat, kijkt men naar de kapotte pixels en vult men daar de gemiddelde waarde van de naburige epixels in. Dat werkt prima voor een foto van een bloem of een gezicht. Daar zie je niets van.’ Maar pixels hebben ook een verschillende kwaliteit in gevoeligheid. De kwaliteit van de naburige pixels is niet constant; iedere pixel heeft zijn eigen kenmerken.’
Betrouwbaarder beeld
‘Bij een röntgenfoto wil je weten of een donkere vlek een cluster kankercellen is of slechts een verzameling lichtzwakke pixels. En juist met dit soort camera’s worden duizenden foto’s gemaakt. Het begin van het optimalisatieproces is de kenmerken van de pixels te analyseren op grond van de opgenomen beelden’, zegt Van Heel. ‘Als je die kenmerken vervolgens statistisch met elkaar vergelijkt, kun je van iedere pixel de kwaliteit registreren, normeren én corrigeren, en daarmee een betrouwbaarder beeld creëren. De statistiek die je daarvoor nodig hebt, is dus echt van middelbareschoolniveau.’ De reacties van de peers op Van Heels artikel hadden dan ook iets van ongeloof en verbazing: ‘Dat ik daar zelf nooit aan gedacht heb.’ Het is een klassiek voorbeeld van het ei van Columbus.
Eenvoudige middelbareschoolstatistiek
Wat is nu het revolutionaire maar toch kinderlijk eenvoudige aan Van Heels methode? ‘Het gaat eigenlijk om eenvoudige middelbareschoolstof op het gebied van gemiddelden en standaarddeviaties’, vertelt Van Heel. ‘Het is haast pijnlijk dat nooit eerder iemand daarop is gekomen.’ Toch is dat ook wel weer begrijpelijk, want we kijken nu eenmaal met een ruim honderdjarige historie van de fotografie naar individuele foto’s. Van Heel: ‘In de analoge fotografie maakte je één plaatje en als dat helder en scherp was, was je blij, was het onscherp, dan had je pech.’
NeCEN
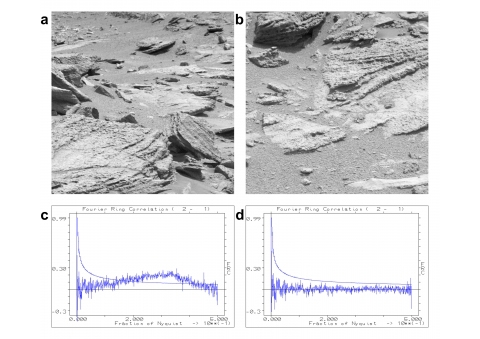
Om de methode te testen hebben Van Heel en zijn collegas aan het Leidse Netherlands Centre for Electron Nanoscopy (NeCEN) en het Imperial College in Londen duizenden beelden van de geavanceerde NeCEN microscopen geanalyseerd. Ook hebben zij ongeveer duizend foto’s van een camera van de marsrover Curiosity gedownload en bestudeerd. (Zie ook afbeelding 2.) Van Heel: ‘Zo’n Marsmissie kost miljarden en als je achteraf, aan de hand van de vele gemaakte foto’s, de resultaten kunt verbeteren is dat een enorm wetenschappelijk - en economisch - voordeel.’
Zie ook
•
Nature, Scientific Report: correction of camera characteristics from large image data sets
•
NeCEN