Detecting Fraud in Waste Transportation Data
Over the past decades within the European Union (EU), economic proliferation and globalisation have resulted in an increase in transboundary waste transportation. Although waste trading can often have positive economic and environmental impacts by repurposing natural resources within industrial sectors, waste transportation often involves hazardous materials which pose serious health and environmental risks. Because of this, transporting waste within the EU is a heavily regulated process. The establishing of the List of Waste (LoW) provides EU member states with specific waste identification which promotes waste management, particularly hazardous waste.
All movement of waste is subject to prior notice reports with written consent from all intervening entities, according to current legislation. In the Netherlands, the supervising body for these actions is the ILT (Inspectie Leefomgeving en Transport). Additionally, different waste types (with distinct LoW codes) are encompassed by specific regulations. For example, some waste categories do not require the consent of authorities for transportation. Another key point to note is the dissimilarity in costs regarding the movement of specific waste categories. In particular, hazardous waste transportation entails the identification of the material in question, labelling of hazardousness, proper waste accommodation, and higher deposit fees, to name a few. Amongst other protocols, entities must provide a waste type-specific financial guarantee towards all associated transport risks. As a result, companies have economic incentive to purposefully mislabel their waste, posing economic, environmental, and health risks. Therefore, targeting these cases is of utmost importance.
Crossliers
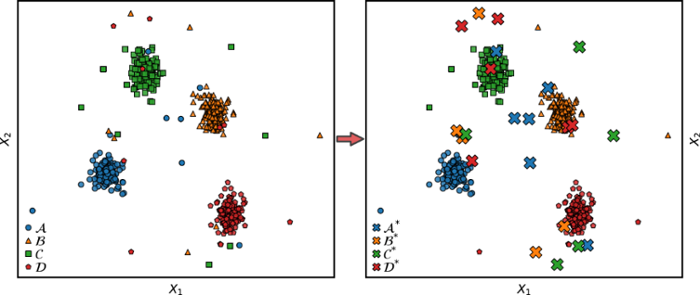
Since inspectors of ILT cannot accurately assess all permits given the volume of data, automatic methods must be deployed. We propose a novel method which specifically addresses mislabels in waste transportation data. Fig. 1 illustrates this concept: classes A, B, C, and D represent different waste categories, while A∗, B∗, C∗, and D∗ indicate potentially manipulated waste categories; we call these instances crossliers.
We advocate that by learning to separate a given category from all others, the furthest samples from the category boundary (and therefore the most uncertain samples given their waste category) are most likely erroneous. By assisting domain experts in their task of selecting probable waste mislabels, we ultimately help shift the current paradigm away from purely knowledge-based inspections, towards data-driven approaches and applications in this domain.
The full detailed version of our work “The eXPose Approach to Crosslier Detection” can be seen in Proceedings of the 25th IEEE International Conference on Pattern Recognition 2020.